
{kind=link}

Рисунок 1: «Интерактивное обучение флота» (IFL) относится к паркам роботов в промышленности и академических кругах, которые при необходимости прибегают к телеоператорам-людям и постоянно учатся у них с течением времени.
В последние несколько лет мы наблюдаем захватывающее развитие робототехники и искусственного интеллекта: большие флоты роботов покинули лабораторию и вошли в реальный мир. У Waymo, например, есть более 700 беспилотных автомобилей, работающих в Фениксе и Сан-Франциско, и в настоящее время они расширяются до Лос-Анджелеса. Другие промышленные развертывания парка роботов включают такие приложения, как выполнение заказов электронной коммерции в Amazon и Ambi Robotics, а также доставку еды в Nuro и Kiwibot.

Коммерческое и промышленное развертывание парков роботов: доставка посылок (вверху слева), доставка еды (внизу слева), выполнение заказов электронной коммерции в Ambi Robotics (вверху справа), автономные такси в Waymo (внизу справа).
Эти роботы используют последние достижения в области глубокого обучения для автономной работы в неструктурированных средах. Путем объединения данных от всех роботов в парке весь парк может эффективно учиться на опыте каждого отдельного робота. Кроме того, благодаря достижениям в области облачной робототехники флот может выгружать данные, память и вычисления (например, обучение больших моделей) в облако через Интернет. Этот подход известен как «обучение автопарка» — термин, популяризированный Илоном Маском в пресс-релизах об автопилоте Tesla в 2016 году и используемый в сообщениях для прессы исследовательским институтом Toyota, Wayve AI и другими. Флот роботов — современный аналог флота кораблей, где слово флот имеет этимологию, восходящую к флот («корабль») и флеотан («плавать») на древнеанглийском языке.
Однако подходы, основанные на данных, такие как обучение автопарка, сталкиваются с проблемой «длинного хвоста»: роботы неизбежно сталкиваются с новыми сценариями и крайними случаями, которые не представлены в наборе данных. Естественно, мы не можем ожидать, что будущее будет таким же, как прошлое! Как же тогда эти компании, производящие робототехнику, могут обеспечить достаточную надежность своих услуг?
Один из ответов — обратиться к удаленным людям через Интернет, которые могут в интерактивном режиме взять на себя управление и «управлять» системой, когда политика роботов ненадежна во время выполнения задачи. Телеуправление имеет богатую историю в робототехнике: первые в мире роботы использовались дистанционно во время Второй мировой войны для работы с радиоактивными материалами, а компания Telegarden стала пионером в управлении роботами через Интернет в 1994 году. Благодаря постоянному обучению данные о телеоперациях человека, полученные в результате этих вмешательств, могут итеративно улучшать политику в отношении роботов. и со временем уменьшить зависимость роботов от своих руководителей-людей. Вместо дискретного перехода к полной автономии роботов эта стратегия предлагает непрерывную альтернативу, которая со временем приближается к полной автономии, одновременно обеспечивая надежность робототехнических систем. сегодня.
Использование телеуправления человеком в качестве резервного механизма становится все более популярным в современных робототехнических компаниях: Waymo называет это «реагированием флота», Zoox называет это «Телегид», и Amazon называет это «постоянным обучением». В прошлом году программная платформа для удаленного вождения под названием Phantom Auto была признана журналом Time одним из 10 лучших изобретений 2022 года. И только в прошлом месяце John Deere приобрела SparkAI, стартап, который разрабатывает программное обеспечение для решения крайних случаев с участием людей в петля.

Удаленный телеоператор в Phantom Auto, программной платформе для удаленного вождения через Интернет.
Однако, несмотря на эту растущую тенденцию в промышленности, в научных кругах этой теме уделялось сравнительно мало внимания. В результате робототехническим компаниям пришлось полагаться на специальные решения для определения того, когда их роботы должны уступить контроль. Ближайшим аналогом в академических кругах является интерактивное имитационное обучение (IIL), парадигма, в которой робот периодически передает управление человеку-наблюдателю и со временем учится на этих вмешательствах. В последние годы было разработано несколько алгоритмов IIL для настройки с одним роботом и одним человеком, включая DAgger и его варианты, такие как HG-DAgger, SafeDAgger, EnsembleDAgger и ThriftyDAgger; тем не менее, когда и как переключаться между управлением роботом и человеком, остается открытой проблемой. Это еще менее понятно, когда это понятие обобщается на флоты роботов с несколькими роботами и несколькими людьми-надзирателями.
Формализм и алгоритмы IFL
С этой целью в недавней статье на конференции по обучению роботов мы представили парадигму Интерактивное обучение флоту (IFL), первый формализм в литературе для интерактивного обучения с несколькими роботами и несколькими людьми. Поскольку мы видели, что это явление уже имеет место в промышленности, теперь мы можем использовать фразу «интерактивное обучение парка роботов» в качестве единой терминологии для обучения парка роботов, которое зависит от человеческого контроля, вместо того, чтобы отслеживать названия каждого отдельного корпоративного решения. («Ответ автопарка», «Телеуправление» и др.). IFL расширяет возможности обучения роботов с помощью четырех ключевых компонентов:
- Надзор по требованию. Поскольку люди не могут эффективно контролировать выполнение нескольких роботов одновременно и склонны к утомлению, распределение роботов среди людей в IFL автоматизировано с помощью некоторой политики распределения $\omega$. Роботы запрашивают надзор «по требованию», а не возлагают бремя непрерывного наблюдения на людей.
- Надзор за флотом. Контроль по запросу позволяет эффективно распределять ограниченное внимание человека на большой парк роботов. IFL позволяет значительно увеличить количество роботов по сравнению с людьми (например, в 10:1 и более раз).
- Непрерывное обучение. Каждый робот в парке может учиться на своих ошибках, а также на ошибках других роботов, что позволяет со временем уменьшить объем необходимого человеческого контроля.
- Интернет. Благодаря зрелым и постоянно совершенствующимся интернет-технологиям, человеку-супервайзеру не нужно физически присутствовать. Современные компьютерные сети позволяют осуществлять удаленную дистанционную работу в режиме реального времени на огромных расстояниях.
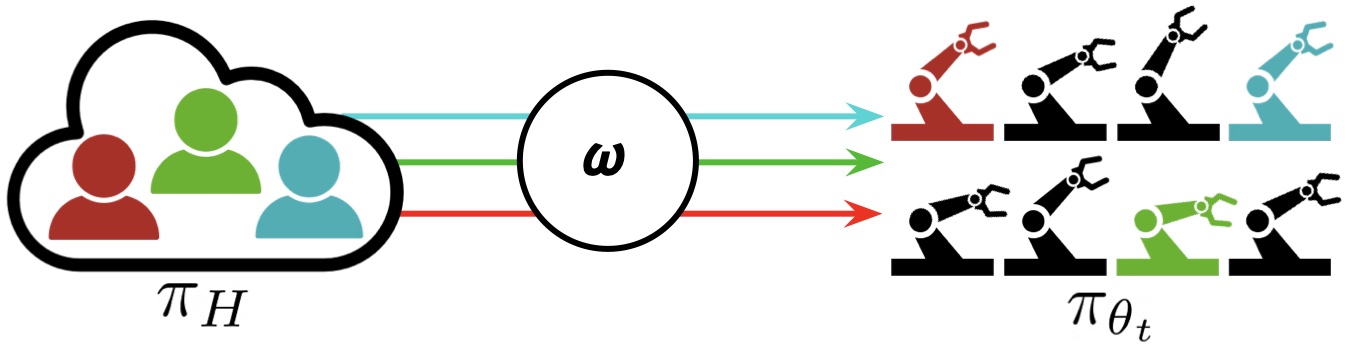
В парадигме интерактивного обучения флота (IFL) M человек назначаются роботам, которые больше всего нуждаются в помощи, в парке из N роботов (где N может быть намного больше, чем M). Роботы разделяют политику $\pi_{\theta_t}$ и со временем учатся на вмешательстве человека.
Мы предполагаем, что у роботов общая политика управления $\pi_{\theta_t}$, а у людей общая политика управления $\pi_H$. Мы также предполагаем, что роботы работают в независимых средах с идентичными пространствами состояний и действий (но не идентичными состояниями). В отличие от робота рой обычно недорогих роботов, которые координируют свои действия для достижения общей цели в общей среде, робот флот одновременно выполняет общую политику в разных параллельных средах (например, в разных бункерах на сборочной линии).
Цель IFL — найти оптимальную политику распределения супервизоров $\omega$, отображение из $\mathbf{s}^t$ (состояние всех роботов в момент времени). т) и общую политику $\pi_{\theta_t}$ в бинарную матрицу, указывающую, какой человек будет назначен какому роботу в определенный момент времени. т. Цель IFL — это новая метрика, которую мы называем «окупаемость человеческих усилий» (ROHE):
\[\max_{\omega \in \Omega} \mathbb{E}_{\tau \sim p_{\omega, \theta_0}(\tau)} \left[\frac{M}{N} \cdot \frac{\sum_{t=0}^T \bar{r}( \mathbf{s}^t, \mathbf{a}^t)}{1+\sum_{t=0}^T \|\omega(\mathbf{s}^t, \pi_{\theta_t}, \cdot) \|^2 _F} \right]\]
где числитель — это общее вознаграждение для роботов и временных шагов, а знаменатель — общее количество человеческих действий для роботов и временных шагов. Интуитивно, ROHE измеряет производительность парка, нормализованную требуемым общим человеческим контролем. См. статью для получения дополнительных математических деталей.
Используя этот формализм, мы теперь можем создавать и сравнивать алгоритмы IFL (т. е. политики распределения) принципиальным образом. Мы предлагаем семейство алгоритмов IFL под названием Fleet-DAgger, где алгоритм обучения политике представляет собой интерактивное имитационное обучение, а каждый алгоритм Fleet-DAgger параметризуется уникальной функцией приоритета $\hat p: (s, \pi_{\theta_t}) \ rightarrow[0\infty)$которыйкаждыйроботвпаркеиспользуетдляприсвоениясебеоценкиприоритетаКакивтеориипланированияроботысболеевысокимприоритетомсбольшейвероятностьюпривлекутвниманиечеловекаFleet-DAggerявляетсядостаточнообщимдлямоделированияширокогоспектраалгоритмовIFLвключаяIFL-адаптациисуществующихалгоритмовIILдляодногороботаиодногочеловекатакихкакEnsembleDAggerиThriftyDAggerОбратитевниманиеоднакочтоформализмIFLнеограничиваетсяFleet-DAgger:изучениеполитикиможетвыполнятьсянапримерспомощьюалгоритмаобучениясподкреплениемтакогокакPPO[0\infty)$thateachrobotinthefleetusestoassignitselfapriorityscoreSimilartoschedulingtheoryhigherpriorityrobotsaremorelikelytoreceivehumanattentionFleet-DAggerisgeneralenoughtomodelawiderangeofIFLalgorithmsincludingIFLadaptationsofexistingsingle-robotsingle-humanIILalgorithmssuchasEnsembleDAggerandThriftyDAggerNotehoweverthattheIFLformalismisn’tlimitedtoFleet-DAgger:policylearningcouldbeperformedwithareinforcementlearningalgorithmlikePPOforinstance
Тест IFL и эксперименты
Чтобы определить, как лучше распределить ограниченное внимание человека на большой парк роботов, нам необходимо иметь возможность эмпирически оценивать и сравнивать различные алгоритмы IFL. С этой целью мы представляем IFL Benchmark, набор инструментов Python с открытым исходным кодом, доступный на Github, чтобы облегчить разработку и стандартизированную оценку новых алгоритмов IFL. Мы расширяем NVIDIA Isaac Gym, высокооптимизированную программную библиотеку для сквозного обучения роботов с ускорением на GPU, выпущенную в 2021 году, без которой моделирование сотен или тысяч обучающихся роботов было бы невозможным с вычислительной точки зрения. Используя IFL Benchmark, мы проводим крупномасштабные эксперименты по моделированию с Н = 100 роботов, М = 10 алгоритмических людей, 5 алгоритмов IFL и 3 многомерные среды непрерывного управления (рис. 1, слева).
Мы также оцениваем алгоритмы IFL в реальной задаче проталкивания блоков на основе изображений с помощью Н = 4 руки робота и М = 2 удаленных человека-телеоператора (рис. 1, справа). Четыре руки принадлежат двум бимануальным роботам ABB YuMi, работающим одновременно в двух отдельных лабораториях на расстоянии около 1 километра друг от друга, а удаленные люди в третьем физическом месте выполняют телеоперации через интерфейс клавиатуры по запросу. Каждый робот толкает куб к уникальной целевой позиции, выбранной случайным образом в рабочей области; цели генерируются программно в наблюдениях роботов над головой и автоматически передискретизируются при достижении предыдущих целей. Результаты физических экспериментов указывают на тенденции, которые примерно соответствуют наблюдаемым в эталонных средах.
Выводы и будущие направления
Чтобы устранить разрыв между теорией и практикой обучения роботов, а также облегчить будущие исследования, мы представляем новые формализмы, алгоритмы и тесты для интерактивного обучения. Поскольку IFL не диктует конкретную форму или архитектуру общей политики управления роботами, ее можно гибко синтезировать с другими перспективными направлениями исследований. Например, политики распространения, которые недавно продемонстрировали изящную обработку мультимодальных данных, могут использоваться в IFL для реализации разнородных политик супервизора-человека. В качестве альтернативы, многозадачные трансформеры, такие как RT-1 и PerAct, могут быть эффективными «губками данных», которые позволяют роботам в парке выполнять разнородные задачи, несмотря на использование единой политики. Системный аспект IFL — еще одно интересное направление исследований: недавние разработки в области облачной и туманной робототехники позволяют паркам роботов переложить все задачи по распределению супервайзеров, обучению моделей и краудсорсинговым телеоперациям на централизованные серверы в облаке с минимальной задержкой в сети.
В то время как парадокс Моравека до сих пор не позволял робототехнике и воплощенному ИИ в полной мере насладиться недавним впечатляющим успехом, который продемонстрировали модели больших языков (LLM), такие как GPT-4, «горький урок» LLM заключается в том, что контролируемое обучение в беспрецедентных масштабах — это то, что в конечном итоге приводит к эмерджентным свойствам, которые мы наблюдаем. Поскольку у нас еще нет такого количества данных управления роботами, как все текстовые и графические данные в Интернете, парадигма IFL предлагает один путь вперед для расширения контролируемого обучения роботов и надежного развертывания парков роботов в современном мире.
Благодарности
Этот пост основан на документе «Fleet-DAgger: интерактивное обучение роботов с масштабируемым человеческим контролем», представленном на 6-й ежегодной конференции по обучению роботов (CoRL) в декабре 2022 года в Окленде, Новая Зеландия. Исследование проводилось в лаборатории AUTOLab Калифорнийского университета в Беркли в сотрудничестве с лабораторией Berkeley AI Research (BAIR) и инициативой CITRIS «Люди и роботы» (CPAR). Авторы были частично поддержаны пожертвованиями от Google, Siemens, Toyota Research Institute и Autodesk, а также грантами на оборудование от PhotoNeo, NVidia и Intuitive Surgical. Любые высказанные мнения, выводы и выводы или рекомендации принадлежат авторам и не обязательно отражают точку зрения спонсоров. Спасибо соавторам Лоуренсу Чену, Сатвику Шарме, Картику Дхармараджану, Бриджену Тананджеяну, Питеру Аббилу и Кену Голдбергу за их вклад и полезные отзывы об этой работе.
Дополнительные сведения об интерактивном обучении автопарка см. в статье на arXiv, видео презентации CoRL на YouTube, кодовой базе с открытым исходным кодом на Github, резюме высокого уровня в Twitter и на сайте проекта.
Если вы хотите процитировать эту статью, пожалуйста, используйте следующий bibtex:
@article{ifl_blog,
title={Interactive Fleet Learning},
author={Hoque, Ryan},
url={https://bair.berkeley.edu/blog/2023/04/06/ifl/},
journal={Berkeley Artificial Intelligence Research Blog},
year={2023}
}