
{kind=link}
Недавно я присутствовал на выступлении Кевина Кларка (CS224n), где он говорил о будущих тенденциях в НЛП. Я пишу этот пост, чтобы подвести итоги и обсудить последние тенденции. Фрагменты слайдов взяты из его гостевой лекции.
Есть две основные темы, определяющие тенденции НЛП с глубоким обучением:
1. Предварительное обучение с использованием неконтролируемых/немаркированных данных
2. Прорыв OpenAI GPT-2
1. Предварительное обучение с использованием неконтролируемых/немаркированных данных
Контролируемые данные дороги и ограничены, как мы можем использовать неконтролируемые данные, чтобы дополнить обучение контролируемой тонкой настройкой, чтобы добиться большего успеха?
Давайте применим это к проблеме машинного перевода и посмотрим, как это поможет —
Если у вас есть 2 корпуса текстов (транскрипции или статьи из Википедии) на разных языках без межъязыкового сопоставления.
Мы можем использовать это для предварительного обучения, обучать кодировщик и декодер LSTM (без внимания) по отдельности на обоих корпусах, сопоставлять их вместе в модели и тонко настраивать помеченный набор данных.

Как это помогает? И кодировщик, и декодер LSTM здесь изучили понятие своих соответствующих языковых дистрибутивов и хороши в качестве генеративных моделей для каждого из своих языков. Когда вы соединяете их вместе (№ 2), модель учится использовать сжатое представление и сопоставляет их с исходным языком на целевой. Предварительное обучение в некотором роде эквивалентно «умной» инициализации. Давайте продолжим.
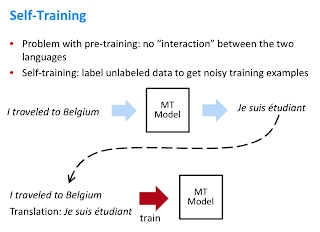
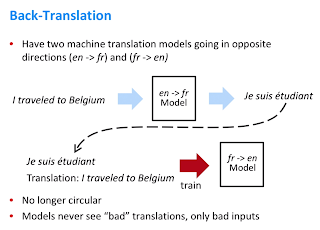
Проблема с предварительным обучением заключается в том, что сеть изначально не была обучена изучению отображения источника в пункт назначения. Давайте посмотрим, как здесь помогает самообучение, применяемое в качестве обратного перевода. Мы используем модель NMT (нейронный машинный перевод) для перевода с английского на французский, а затем передаем выходные данные NMT1 в качестве пары обратных значений в NMT2. Это означает, что, учитывая выходные данные NMT1, модель 2 учится генерировать входные данные. Это скорее «дополненные» контролируемые данные, где, учитывая зашумленный ввод другой модели, ваша сеть учится предсказывать ввод предыдущей модели.
Пока все хорошо, давайте рассмотрим более простой подход к выполнению NMT с нулевыми помеченными данными. Это делается путем изучения векторов слов в обоих языках. Преимущество векторов слов в том, что они имеют внутреннюю структуру. Это позволяет нам изучить аффинное отображение между двумя языками с весом (W) на изображении ниже.
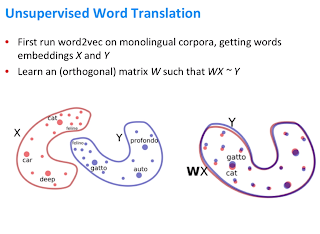
Слова с похожими значениями будут отображаться довольно близко при встраивании пространства между языками. Теперь, используя их в наших предыдущих кодировщике и декодере, мы можем обучить сеть выполнять перевод между языками, поскольку теперь мы знаем значение слов на обоих языках.
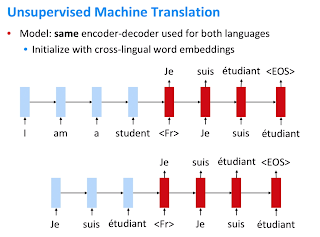
Краткое изложение целевых функций оптимизации:
- Один и тот же кодировщик обучается дважды, один раз, чтобы научиться воспроизводить исходный язык обратно в режиме автоматического кодирования, это помогает сети еще больше закрепить сопоставление исходного и целевого языков через – Src -> Target -> Src Learning.
- Во-вторых, использование контролируемых данных для выполнения обратного преобразования с использованием вывода другой сети.
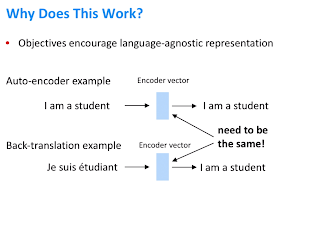
Недавно исследовательская группа в Facebook расширила цель обучения языковой маскировке BERT, чтобы не только маскировать слова на языке, но и предоставлять сетевые входные данные на 2 языках (под наблюдением) и маскировать слова на одном. Таким образом, заставить его изучать значение между языками – это обеспечило значительное улучшение производительности, и статья называется Cross-Lingual BERT.
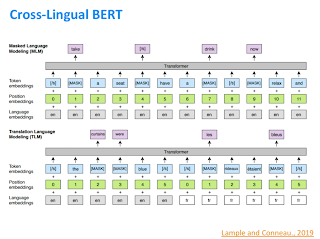
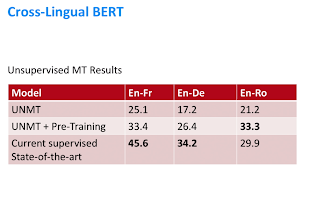
2. ГПТ-2
Далее, давайте посмотрим на модель OpenAI GPT-2. По сути, это ОГРОМНАЯ модель (1,5 миллиарда параметров), обученная на качественных данных (ссылки с высоким рейтингом на Reddit).

GPT-2 обучается как языковая модель, но оценивается во многих задачах, например, оценивается как модель Zero Shot.
(Обучение с нулевым выстрелом означает попытку выполнить задачу, даже не тренируясь на ней.)

Теперь вопрос в том, как мы использовали GPT-2 для выполнения перевода, хотя он никогда явно не обучался выполнять перевод? Ответ на вопрос можно увидеть в приведенном ниже фрагменте корпуса — кавычки переводятся в связке входных данных на другой язык, модель ловко изучает между обоими языками сопоставление, которое она по своей сути использует для выполнения перевода.

Модели продолжали увеличиваться в размерах и лучше справлялись с задачами Vision и Language. Как долго будет продолжаться эта тенденция — вопрос, на который мы с нетерпением ждем ответа в будущем 🙂