

{kind=link}
Диффузионные модели недавно стали стандартом де-факто для создания сложных многомерных выходных данных. Возможно, вы знаете их за их способность создавать потрясающие ИИ-искусства и гиперреалистичные синтетические изображения, но они также добились успеха в других приложениях, таких как разработка лекарств и непрерывный контроль. Ключевая идея моделей диффузии заключается в итеративном преобразовании случайного шума в образец, такой как изображение или структура белка. Обычно это мотивируется задачей оценки максимального правдоподобия, когда модель обучается генерировать выборки, максимально точно соответствующие обучающим данным.
Тем не менее, большинство вариантов использования диффузионных моделей напрямую связаны не с сопоставлением обучающих данных, а с последующей целью. Нам нужно не просто изображение, похожее на существующие изображения, а изображение, имеющее определенный тип внешнего вида; нам нужна не просто физически правдоподобная молекула лекарства, но максимально эффективная. В этом посте мы покажем, как модели распространения можно обучать этим нижестоящим целям непосредственно с помощью обучения с подкреплением (RL). Для этого мы тонко настраиваем Stable Diffusion для различных целей, включая сжимаемость изображения, эстетическое качество, воспринимаемое человеком, и оперативное выравнивание изображения. Последняя из этих целей использует обратную связь от большой модели языка видения, чтобы улучшить производительность модели при необычных подсказках, демонстрируя, как мощные модели ИИ могут использоваться для улучшения друг друга без участия человека.
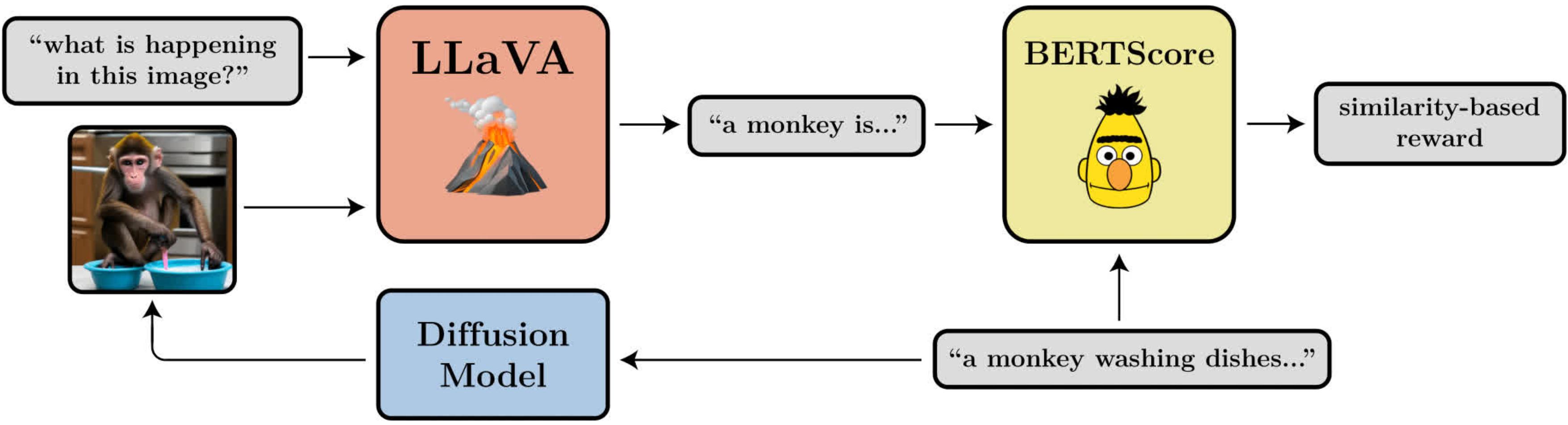
Диаграмма, иллюстрирующая цель выравнивания изображения-подсказки. Он использует LLaVA, большую языковую модель видения, для оценки сгенерированных изображений.
Оптимизация политик шумоподавления
Превращая диффузию в проблему RL, мы делаем только самое основное предположение: при наличии образца (например, изображения) у нас есть доступ к функции вознаграждения, которую мы можем оценить, чтобы сказать нам, насколько «хорош» этот образец. Наша цель состоит в том, чтобы диффузионная модель генерировала выборки, которые максимизируют эту функцию вознаграждения.
Диффузионные модели обычно обучаются с использованием функции потерь, полученной из оценки максимального правдоподобия (MLE), что означает, что им рекомендуется генерировать выборки, которые делают обучающие данные более вероятными. В настройках RL у нас больше нет обучающих данных, только образцы из модели распространения и связанные с ними вознаграждения. Один из способов, которым мы все еще можем использовать ту же функцию потерь, мотивированную MLE, — это рассматривать образцы как обучающие данные и включать вознаграждения, взвешивая потери для каждого образца по его вознаграждению. Это дает нам алгоритм, который мы называем регрессией, взвешенной по вознаграждению (RWR), в честь существующих алгоритмов из литературы по RL.
Тем не менее, есть несколько проблем с этим подходом. Во-первых, RWR не является особо точным алгоритмом — он лишь приблизительно максимизирует вознаграждение (см. Nair et. al., Приложение A). Вдохновленные MLE потери для диффузии также не являются точными и вместо этого выводятся с использованием вариационной границы истинной вероятности каждой выборки. Это означает, что RWR максимизирует вознаграждение за счет двух уровней приближения, что, как мы обнаружили, значительно снижает его производительность.
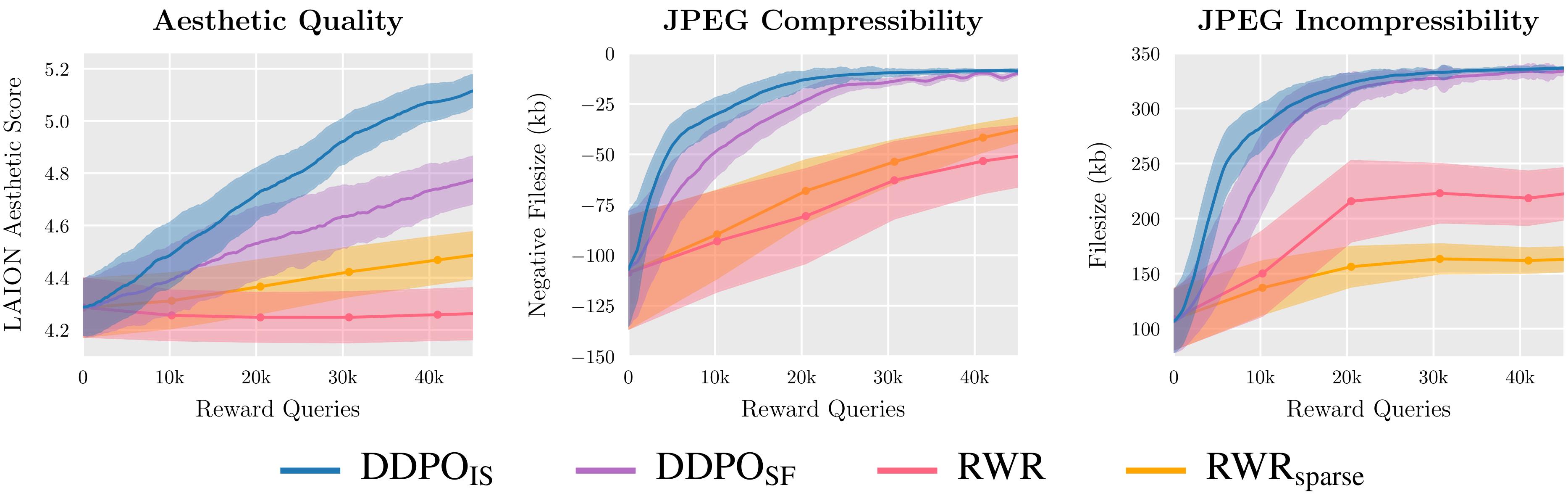
Мы оцениваем два варианта DDPO и два варианта RWR по трем функциям вознаграждения и обнаруживаем, что DDPO стабильно обеспечивает наилучшие результаты.
Ключевым моментом нашего алгоритма, который мы называем оптимизацией политики диффузии шумоподавления (DDPO), является то, что мы можем лучше максимизировать вознаграждение за окончательный образец, если обратим внимание на всю последовательность шагов шумоподавления, которые привели нас к этому. Для этого мы переформулируем процесс диффузии как многошаговый марковский процесс принятия решений (MDP). В терминологии MDP: каждый шаг шумоподавления — это действие, и агент получает вознаграждение только на последнем шаге каждой траектории шумоподавления, когда создается окончательный образец. Эта структура позволяет нам применять многие мощные алгоритмы из литературы по RL, разработанные специально для многоэтапных MDP. Вместо того, чтобы использовать приблизительную вероятность конечной выборки, эти алгоритмы используют точную вероятность каждого шага шумоподавления, которую чрезвычайно легко вычислить.
Мы решили применить алгоритмы градиента политики из-за простоты их реализации и прошлых успехов в тонкой настройке языковой модели. Это привело к двум вариантам DDPO: DDPOСФ, который использует простую функцию оценки градиента политики, также известную как REINFORCE; и ДДПОЯВЛЯЕТСЯ, который использует более мощную выборочную оценку важности. ДДПОЯВЛЯЕТСЯ — наш самый эффективный алгоритм, и его реализация очень похожа на проксимальную оптимизацию политик (PPO).
Тонкая настройка стабильной диффузии с использованием DDPO
Для наших основных результатов мы настраиваем Stable Diffusion v1-4 с использованием DDPO.ЯВЛЯЕТСЯ. У нас есть четыре задачи, каждая из которых определяется своей функцией вознаграждения:
- Сжимаемость: насколько легко изображение сжимается с помощью алгоритма JPEG? Наградой является отрицательный размер файла изображения (в килобайтах) при сохранении в формате JPEG.
- Несжимаемость: насколько сложно сжать изображение с помощью алгоритма JPEG? Наградой является положительный размер файла изображения (в килобайтах) при сохранении в формате JPEG.
- Эстетическое качество: Насколько эстетически привлекательно изображение для человеческого глаза? Наградой является результат эстетического предсказателя LAION, который представляет собой нейронную сеть, обученную на человеческих предпочтениях.
- Выравнивание изображения подсказки: насколько хорошо изображение отображает то, что было запрошено в подсказке? Это немного сложнее: мы загружаем изображение в LLaVA, просим его описать изображение, а затем вычисляем сходство между этим описанием и исходной подсказкой, используя BERTScore.
Поскольку Stable Diffusion — это модель преобразования текста в изображение, нам также необходимо выбрать набор подсказок, которые будут подаваться во время тонкой настройки. Для первых трех задач используем простые подсказки вида «а(н) [animal]”. Для выравнивания изображения подсказки мы используем подсказки формы «а(н) [animal] [activity]”где деятельность “мыть посуду”, «играть в шахматы»и «езда на велосипеде». Мы обнаружили, что Stable Diffusion часто изо всех сил пытался создать изображения, соответствующие подсказке для этих необычных сценариев, оставляя много возможностей для улучшения с помощью тонкой настройки RL.
Во-первых, мы проиллюстрируем эффективность DDPO на простых вознаграждениях (сжимаемость, несжимаемость и эстетическое качество). Все изображения генерируются с одним и тем же случайным начальным числом. В верхнем левом квадранте мы иллюстрируем, что «ванильное» стабильное распространение генерирует для девяти разных животных; все модели с тонкой настройкой RL показывают четкую качественную разницу. Интересно, что модель эстетического качества (вверху справа) имеет тенденцию к минималистичным черно-белым линейным рисункам, раскрывающим виды изображений, которые предсказатель эстетики LAION считает «более эстетичными».

Затем мы продемонстрируем DDPO на более сложной задаче выравнивания изображения подсказки. Здесь мы показываем несколько снимков из процесса обучения: каждая серия из трех изображений показывает образцы для одного и того же приглашения и случайного начального числа с течением времени, причем первый образец поступает из vanilla Stable Diffusion. Интересно, что модель смещается в сторону более мультяшного стиля, что не было преднамеренным. Мы предполагаем, что это связано с тем, что животные, выполняющие действия, подобные человеческим, с большей вероятностью будут выглядеть в мультяшном стиле в данных предварительной подготовки, поэтому модель переходит к этому стилю, чтобы легче согласовываться с подсказкой, используя то, что она уже знает.

Неожиданное обобщение
Было обнаружено, что при точной настройке больших языковых моделей с помощью RL возникают неожиданные обобщения: например, модели, настраиваемые на выполнение инструкций только на английском языке. часто улучшаются на других языках. Мы обнаружили, что то же самое явление происходит с моделями диффузии текста в изображение. Например, наша модель эстетического качества была настроена с помощью подсказок, выбранных из списка 45 распространенных животных. Мы обнаруживаем, что оно распространяется не только на невидимых животных, но и на предметы повседневного обихода.

В нашей модели выравнивания подсказок во время обучения использовался тот же список из 45 обычных животных и только три действия. Мы обнаруживаем, что он распространяется не только на невидимых животных, но и на невидимую деятельность и даже на новые комбинации того и другого.

Излишняя оптимизация
Хорошо известно, что точная настройка функции вознаграждения, особенно изученной, может привести к чрезмерной оптимизации вознаграждения, когда модель использует функцию вознаграждения для достижения высокого вознаграждения бесполезным способом. Наш сеттинг не является исключением: во всех задачах модель в конечном итоге уничтожает любой значимый контент изображения, чтобы максимизировать вознаграждение.

Мы также обнаружили, что LLaVA подвержен типографским атакам: при оптимизации выравнивания относительно подсказок вида “[n] животные”DDPO удалось успешно обмануть LLaVA, вместо этого сгенерировав текст, отдаленно напоминающий правильное число.

В настоящее время не существует универсального метода предотвращения чрезмерной оптимизации, и мы выделяем эту проблему как важную область для будущей работы.
Заключение
Диффузионные модели трудно превзойти, когда речь идет о создании сложных многомерных выходных данных. Однако до сих пор они были в основном успешными в приложениях, целью которых является изучение шаблонов из большого количества данных (например, пар изображение-заголовок). Мы нашли способ эффективно обучать диффузионные модели, выходящий за рамки сопоставления с образцом и не обязательно требующий каких-либо обучающих данных. Возможности ограничены только качеством и креативностью вашей функции вознаграждения.
То, как мы использовали DDPO в этой работе, вдохновлено недавними успехами в тонкой настройке языковой модели. Модели OpenAI GPT, такие как Stable Diffusion, сначала обучаются на огромных объемах интернет-данных; затем они настраиваются с помощью RL для создания полезных инструментов, таких как ChatGPT. Как правило, их функция поощрения определяется человеческими предпочтениями, но у других есть и другие особенности. недавно выяснил, как создавать мощных чат-ботов, используя вместо этого функции вознаграждения, основанные на отзывах ИИ. По сравнению с режимом чат-ботов наши эксперименты невелики и ограничены по масштабам. Но, учитывая огромный успех этой парадигмы «предварительная подготовка + точная настройка» в языковом моделировании, определенно кажется, что в мире диффузионных моделей стоит продолжать ее дальнейшее развитие. Мы надеемся, что другие смогут использовать нашу работу для улучшения больших моделей распространения не только для преобразования текста в изображение, но и для многих интересных приложений, таких как создание видео, создание музыки, редактирование изображений, синтез белка, робототехника и многое другое.
Кроме того, парадигма «предварительная подготовка + точная настройка» — не единственный способ использования DDPO. Пока у вас есть хорошая функция вознаграждения, ничто не мешает вам тренироваться с RL с самого начала. Хотя этот параметр еще не изучен, именно здесь могут проявиться сильные стороны DDPO. Чистая RL уже давно применяется в самых разных областях, от игр до роботизированных манипуляций, от ядерного синтеза до проектирования микросхем. Добавление мощной выразительности моделей распространения к смеси может вывести существующие приложения RL на новый уровень или даже открыть новые.
Этот пост основан на следующем документе:
Если вы хотите узнать больше о DDPO, вы можете ознакомиться с документом, веб-сайтом, исходным кодом или получить вес модели на сайте Hugging Face. Если вы хотите использовать DDPO в своем собственном проекте, ознакомьтесь с моей реализацией PyTorch + LoRA, где вы можете настроить Stable Diffusion с менее чем 10 ГБ памяти графического процессора!
Если DDPO вдохновляет вашу работу, пожалуйста, укажите это:
@misc{black2023ddpo,
title={Training Diffusion Models with Reinforcement Learning},
author={Kevin Black and Michael Janner and Yilun Du and Ilya Kostrikov and Sergey Levine},
year={2023},
eprint={2305.13301},
archivePrefix={arXiv},
primaryClass={cs.LG}
}