
{kind=link}
В целом, общие цели Acme заключаются в следующем:
- Чтобы обеспечить воспроизводимость наших методов и результатов — это поможет прояснить, что делает проблему RL сложной или легкой, что редко бывает очевидным.
- Чтобы упростить нам (и сообществу в целом) разработку новых алгоритмов, мы хотим, чтобы следующий агент RL было проще писать всем!
- Для повышения читабельности агентов RL — не должно быть скрытых сюрпризов при переходе от бумаги к коду.
Для достижения этих целей дизайн Acme также устраняет разрыв между крупными, средними и малыми экспериментами. Мы сделали это, тщательно продумав дизайн агентов в самых разных масштабах.
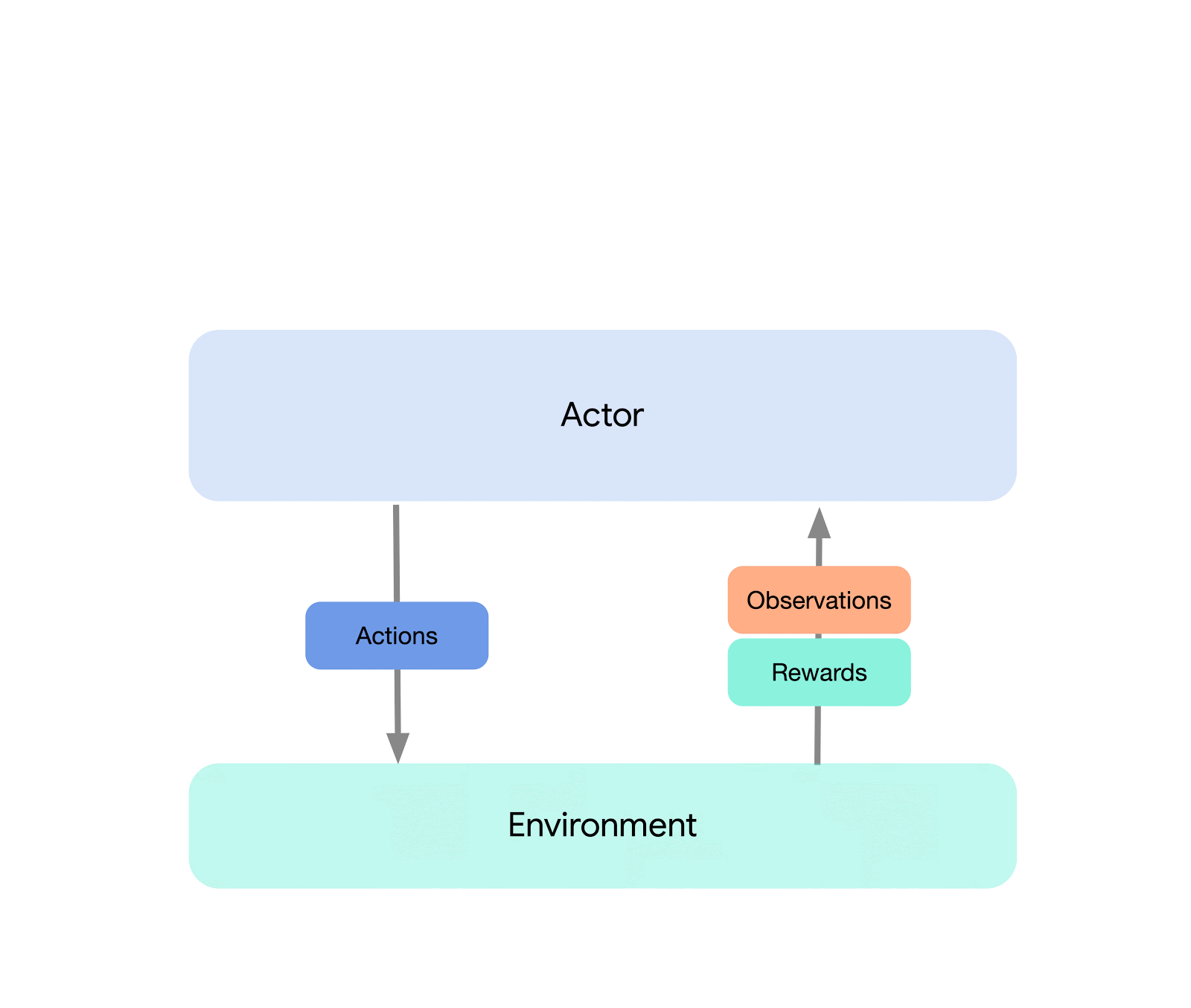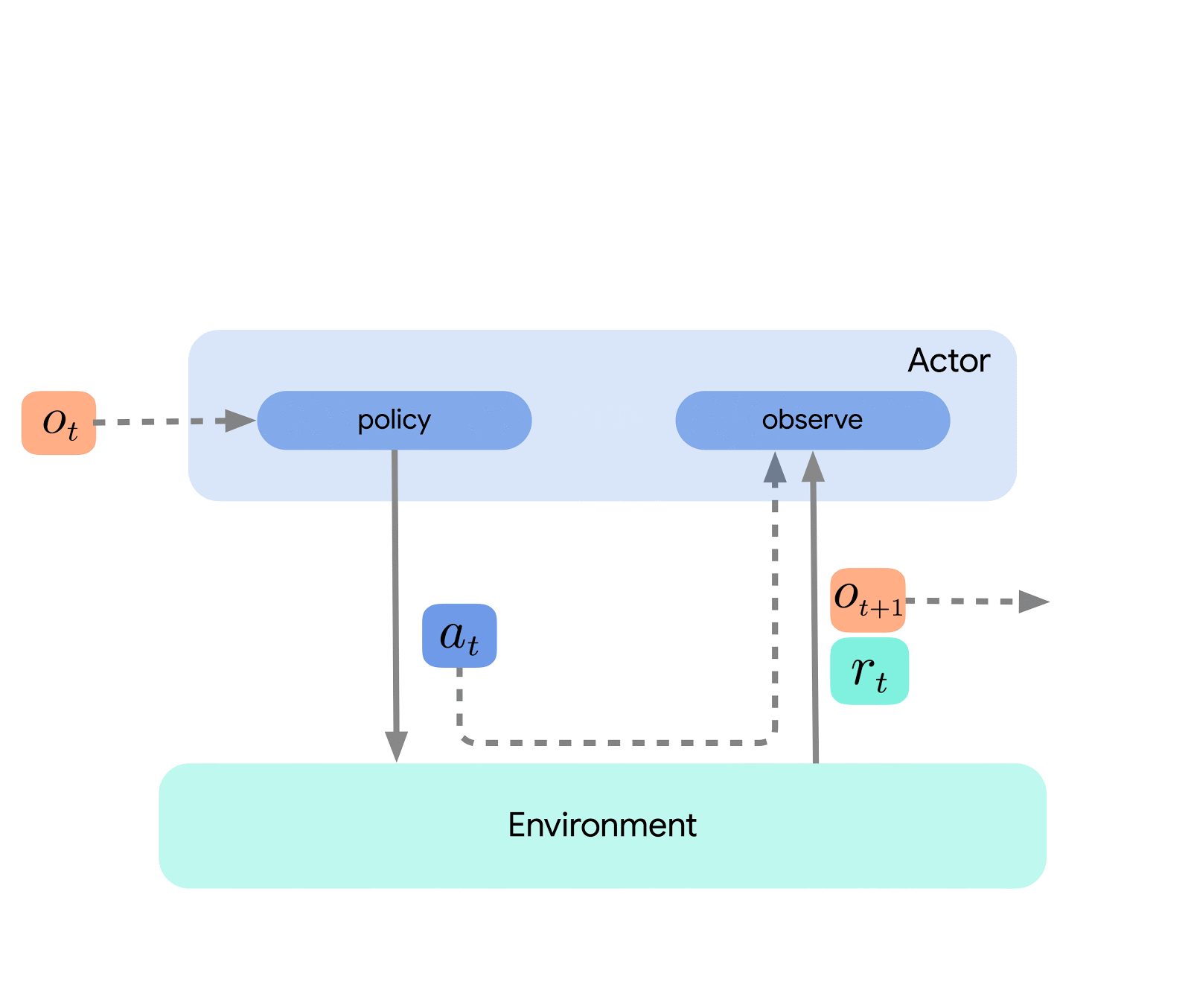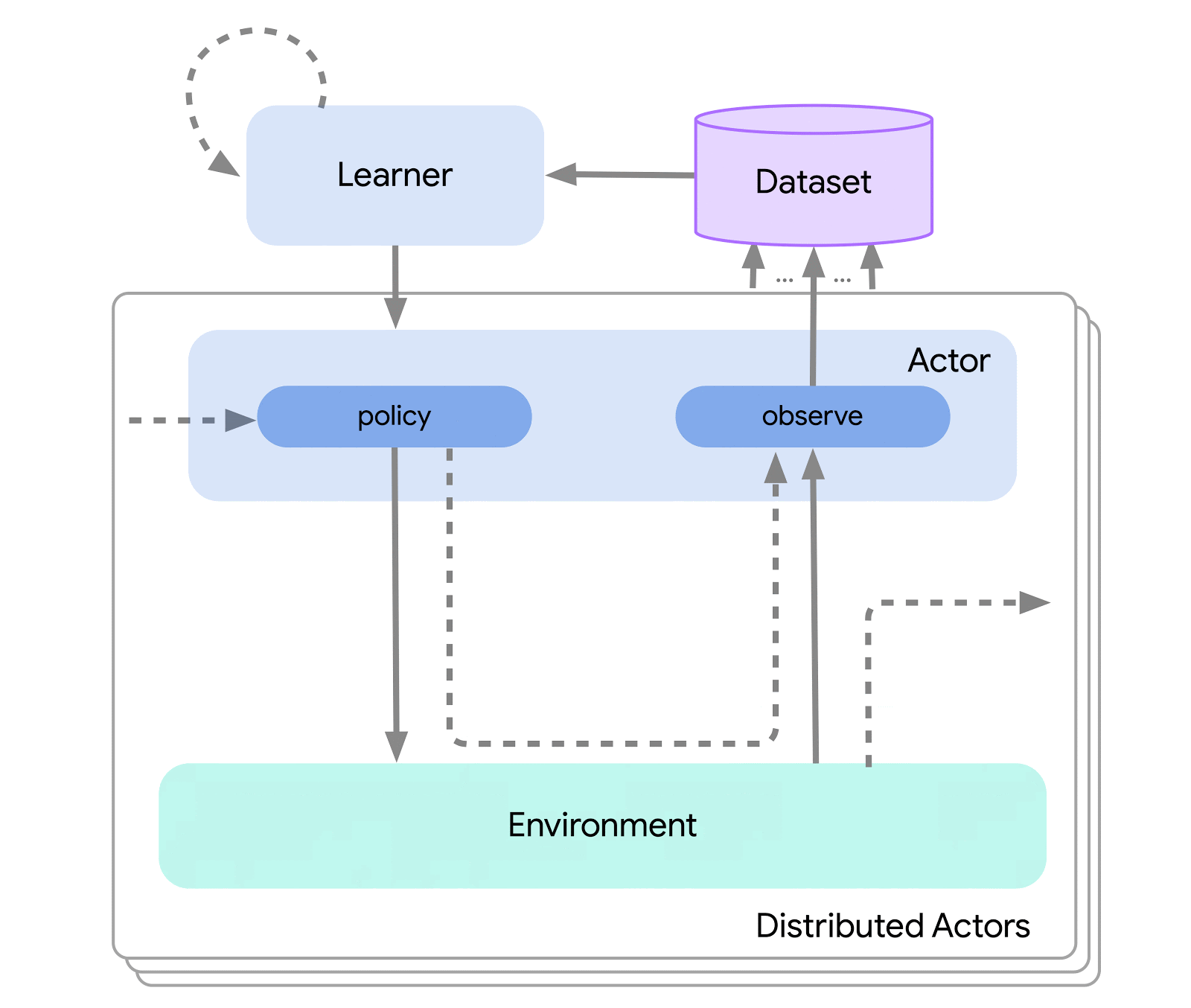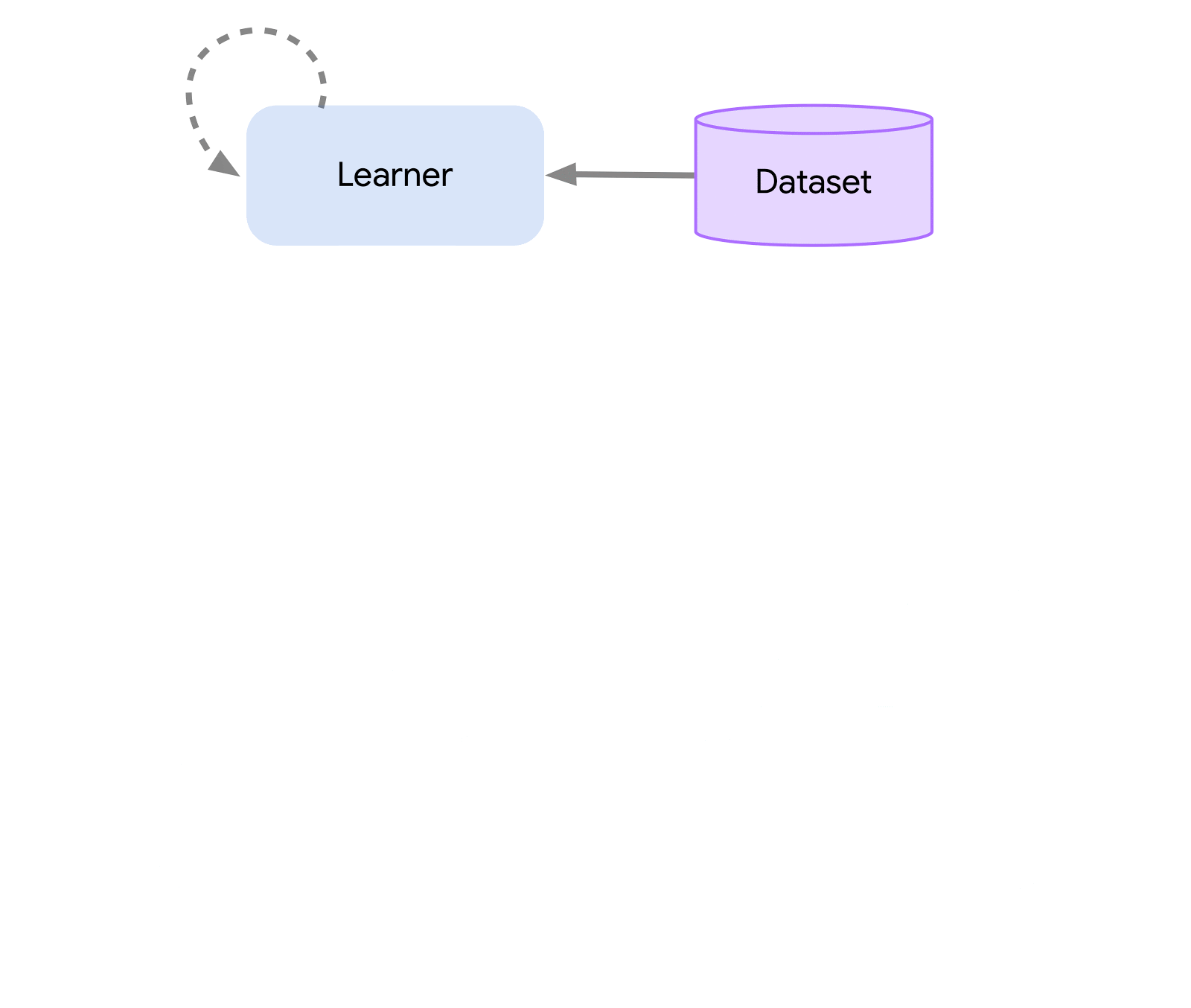
На самом высоком уровне мы можем думать об Acme как о классическом интерфейсе RL (который можно найти в любом вводном тексте RL), который соединяет актера (т. е. агента, выбирающего действие) со средой. Этот актор представляет собой простой интерфейс, который имеет методы для выбора действий, наблюдения и обновления. Внутри агенты обучения дополнительно разделяют проблему на компоненты «действия» и «обучения на основе данных». На первый взгляд, это позволяет нам повторно использовать действующие части во многих различных агентах. Однако, что более важно, это обеспечивает важную границу, на которой можно разделить и распараллелить процесс обучения. Мы можем даже уменьшить масштаб отсюда и беспрепятственно атаковать параметр пакетного RL там, где он существует. нет окружающей среды и только фиксированный набор данных. Иллюстрации этих различных уровней сложности показаны ниже:
Этот дизайн позволяет нам легко создавать, тестировать и отлаживать новые агенты в небольших сценариях, прежде чем масштабировать их — и все это при использовании одного и того же кода действия и обучения. Acme также предоставляет ряд полезных утилит, от создания контрольных точек до моментальных снимков и низкоуровневых вычислительных помощников. Эти инструменты часто являются незамеченными героями любого алгоритма RL, и в Acme мы стремимся сделать их максимально простыми и понятными.
Чтобы реализовать этот дизайн, Acme также использует Reverb: новую эффективную систему хранения данных, специально созданную для данных машинного обучения (и обучения с подкреплением). Реверберация в основном используется как система воспроизведения опыта в алгоритмах распределенного обучения с подкреплением, но она также поддерживает другие представления структур данных, такие как FIFO и очереди с приоритетами. Это позволяет нам беспрепятственно использовать его для алгоритмов политики и вне политики. Acme и Reverb с самого начала разрабатывались так, чтобы прекрасно сочетаться друг с другом, но Reverb можно использовать и сам по себе, так что попробуйте!
Наряду с нашей инфраструктурой мы также выпускаем однопроцессные экземпляры ряда агентов, которые мы создали с помощью Acme. Они включают в себя непрерывный контроль (D4PG, MPO и т. д.), дискретное Q-обучение (DQN и R2D2) и многое другое. С минимальным количеством изменений — путем разделения по границе действия/обучения — мы можем запускать этих же агентов распределенным образом. В нашем первом выпуске основное внимание уделяется однопроцессным агентам, поскольку они в основном используются студентами и практиками-исследователями.
Мы также тщательно протестировали эти агенты в ряде сред, а именно в Control Suite, Atari и bsuite.
Плейлист видеороликов, демонстрирующих агентов, обученных с помощью платформы Acme.
Хотя дополнительные результаты легко доступны в нашей статье, мы показываем несколько графиков, сравнивающих производительность одного агента (D4PG) при измерении как шагов актера, так и времени настенных часов для задачи непрерывного управления. Из-за того, как мы ограничиваем скорость, с которой данные вставляются в воспроизведение — обратитесь к статье для более подробного обсуждения — мы можем увидеть примерно одинаковую производительность при сравнении вознаграждений, получаемых агентом, с количеством взаимодействий. предпринял с окружением (актерские шаги). Однако по мере дальнейшего распараллеливания агента мы видим улучшение скорости обучения агента. В относительно небольших доменах, где наблюдения ограничены небольшим пространством признаков, даже небольшое увеличение этого параллелизма (4 актора) приводит к тому, что агенту требуется менее половины времени для изучения оптимальной политики:

Но для еще более сложных областей, где наблюдения представляют собой изображения, создание которых сравнительно дорого, мы видим гораздо более значительные преимущества:

И выигрыш может быть еще больше для таких областей, как игры Atari, где сбор данных обходится дороже, а процессы обучения обычно занимают больше времени. Однако важно отметить, что эти результаты имеют один и тот же код действия и обучения как в распределенной, так и в нераспределенной среде. Так что вполне возможно экспериментировать с этими агентами и получать результаты в меньшем масштабе — на самом деле это то, что мы постоянно делаем при разработке новых агентов!
Более подробное описание этого дизайна, а также дальнейшие результаты для наших базовых агентов см. в нашей статье. Или, что еще лучше, загляните в наш репозиторий GitHub, чтобы узнать, как вы можете начать использовать Acme для упрощения своих собственных агентов!