
{kind=link}
Представляем RGB-Stacking как новый эталон для роботизированных манипуляций на основе зрения
Взять палку и положить ее на бревно или сложить гальку на камень может показаться человеку простым — и очень похожим — действием. Однако большинству роботов сложно справиться с несколькими такими задачами одновременно. Манипуляции с палкой требуют иного набора действий, чем укладка камней, не говоря уже о том, чтобы ставить одну на другую посуду или собирать мебель. Прежде чем мы сможем научить роботов выполнять такие задачи, им сначала нужно научиться взаимодействовать с гораздо большим количеством объектов. В рамках миссии DeepMind и в качестве шага к созданию более универсальных и полезных роботов мы изучаем, как научить роботов лучше понимать взаимодействие объектов с различной геометрией.
В документе, который будет представлен на CoRL 2021 (Конференция по обучению роботов) и который сейчас доступен в виде препринта на OpenReview, мы представляем RGB-Stacking в качестве нового эталона для манипулирования роботами на основе зрения. В этом тесте робот должен научиться хватать разные объекты и уравновешивать их друг над другом. Что отличает наше исследование от предыдущей работы, так это разнообразие используемых объектов и большое количество эмпирических оценок, выполненных для подтверждения наших выводов. Наши результаты демонстрируют, что сочетание моделирования и реальных данных может использоваться для изучения сложных манипуляций с несколькими объектами, и предлагают прочную основу для открытой проблемы обобщения на новые объекты. Чтобы поддержать других исследователей, мы открываем исходный код версии нашей смоделированной среды и выпускаем проекты для создания нашей среды RGB-стекинга реального робота, а также модели RGB-объектов и информацию для их 3D-печати. Мы также открываем набор библиотек и инструментов, используемых в наших исследованиях в области робототехники.
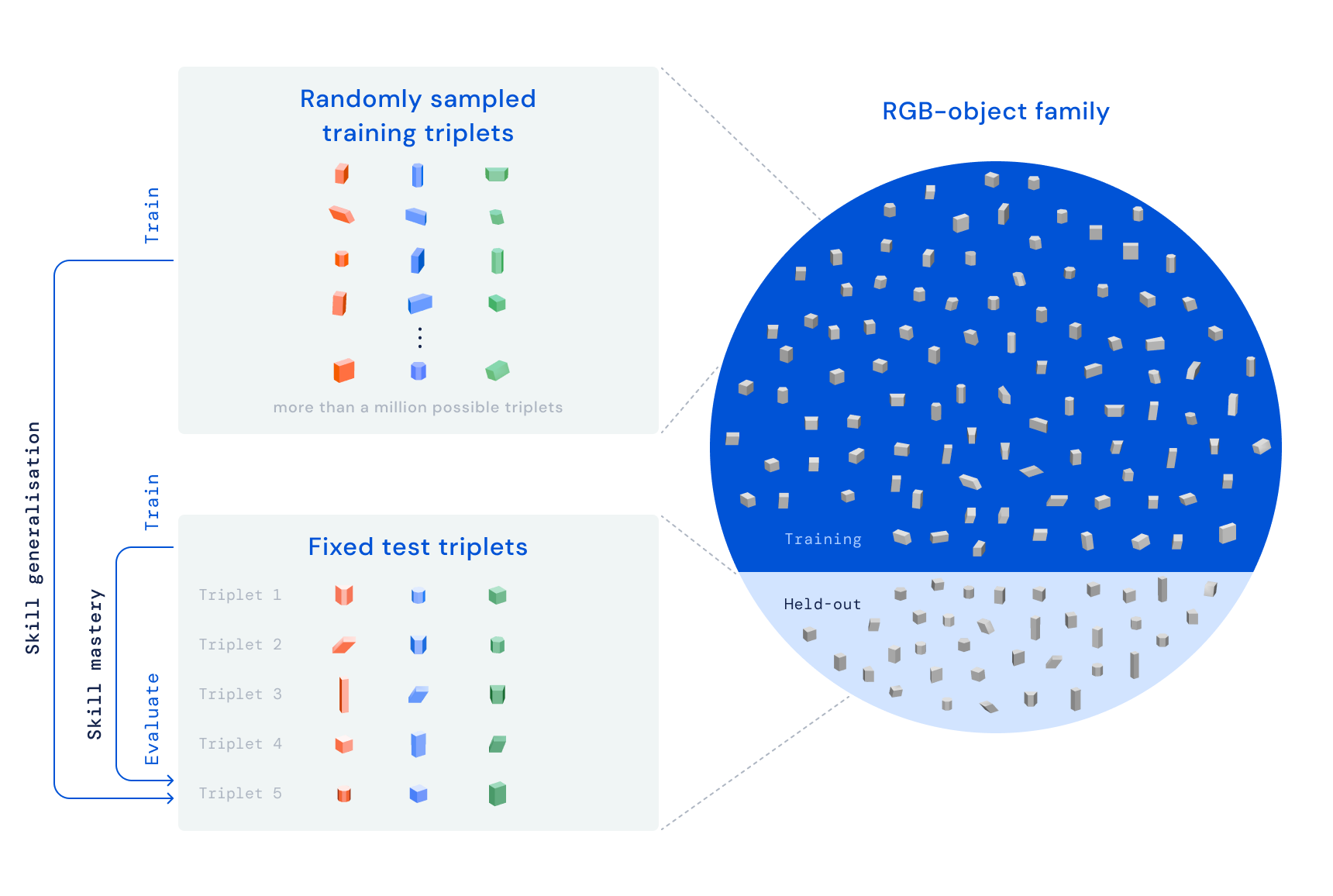
С помощью RGB-Stacking наша цель состоит в том, чтобы научить роботизированную руку с помощью обучения с подкреплением складывать объекты различной формы. Мы размещаем параллельный захват, прикрепленный к руке робота, над корзиной, а в корзине три объекта — один красный, один зеленый и один синий, отсюда и название RGB. Задача проста: сложить красный предмет поверх синего предмета в течение 20 секунд, при этом зеленый предмет служит препятствием и отвлечением. Процесс обучения гарантирует, что агент приобретет общие навыки посредством обучения множеству наборов объектов. Мы намеренно изменяем аффордансы захвата и укладки — качества, которые определяют, как агент может схватить и уложить каждый объект. Этот принцип дизайна заставляет агента демонстрировать поведение, выходящее за рамки простой стратегии «выбери и помести».

Наш тест RGB-Stacking включает в себя две версии задач с разным уровнем сложности. В «Мастерстве навыков» наша цель — обучить одного агента, умеющего складывать заранее заданный набор из пяти троек. В «Обобщении навыков» мы используем те же триплеты для оценки, но обучаем агента на большом наборе обучающих объектов — всего более миллиона возможных триплетов. Для проверки на обобщение эти обучающие объекты исключают семейство объектов, из которых были выбраны тестовые тройки. В обеих версиях мы разделяем наш конвейер обучения на три этапа:
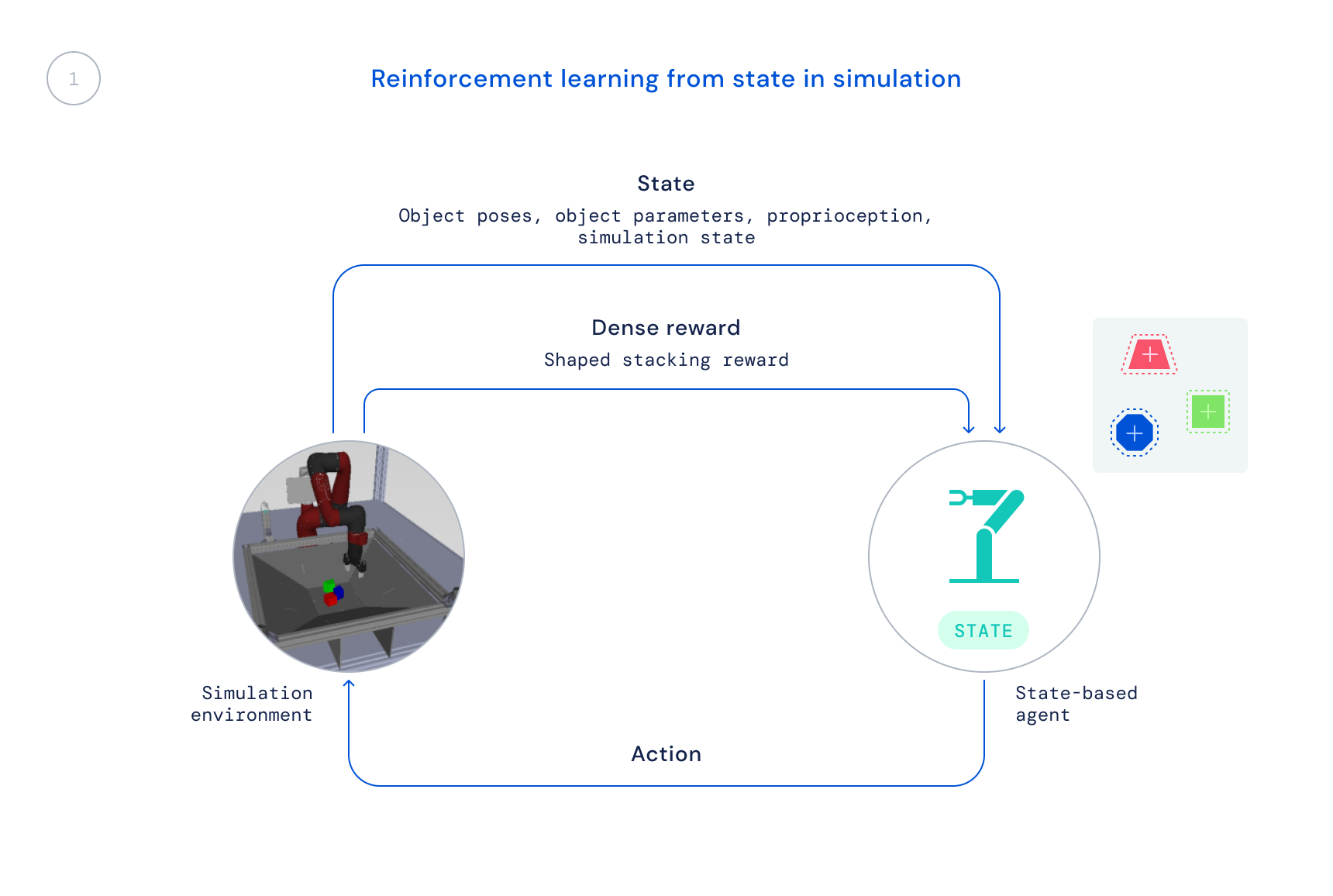
- Во-первых, мы тренируемся в моделировании с использованием готового алгоритма RL: максимальная апостериорная оптимизация политики (MPO). На этом этапе мы используем состояние симулятора, что позволяет проводить быстрое обучение, поскольку позиции объектов передаются непосредственно агенту, вместо того, чтобы агенту приходилось учиться находить объекты на изображениях. Результирующая политика не может быть напрямую передана реальному роботу, поскольку эта информация недоступна в реальном мире.
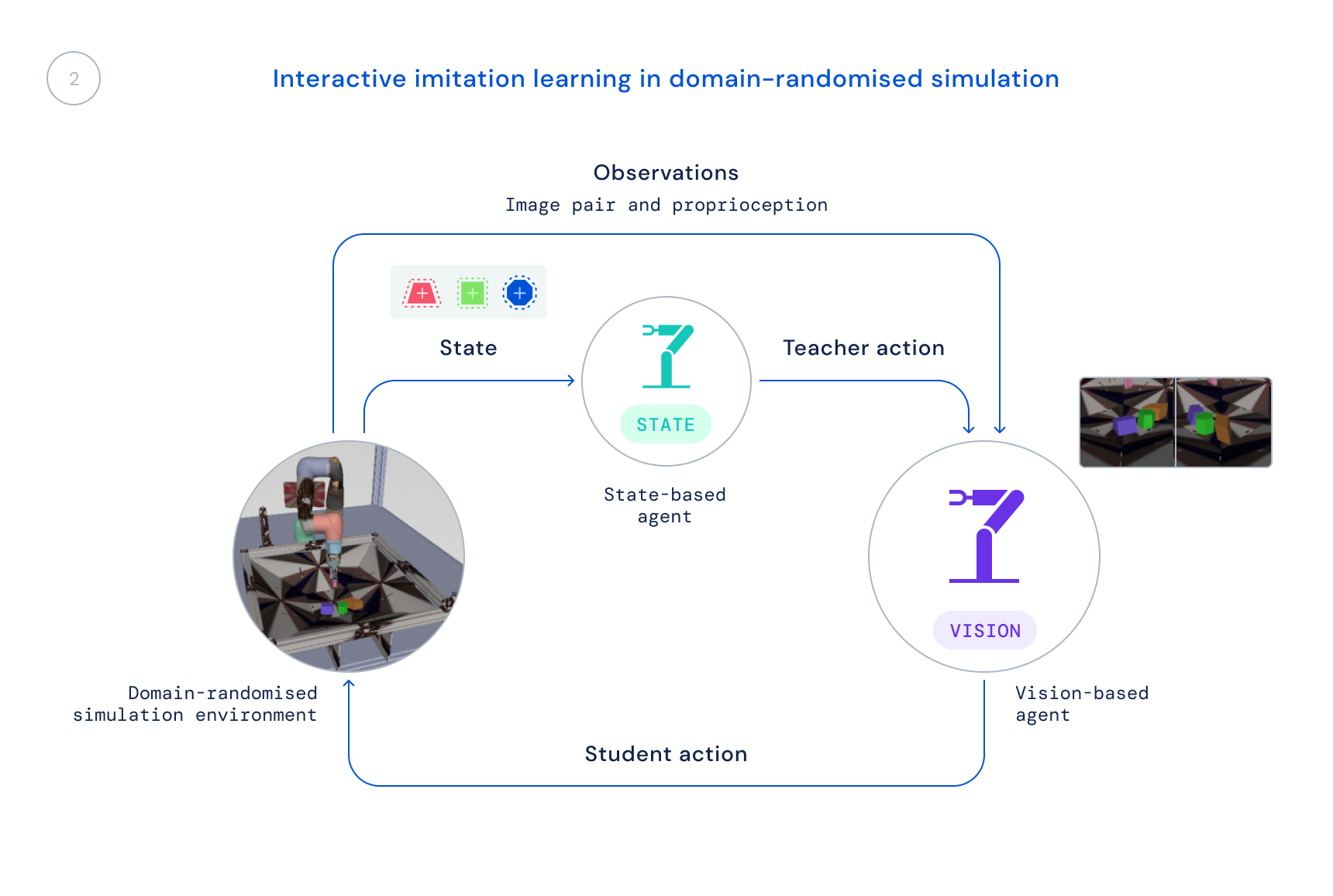
- Затем мы тренируем новую политику в симуляции, которая использует только реалистичные наблюдения: изображения и проприоцептивное состояние робота. Мы используем рандомизированное моделирование доменов, чтобы улучшить передачу реальных изображений и динамики. Государственная политика служит учителем, предоставляя обучающемуся агенту поправки к его поведению, и эти поправки переходят в новую политику.
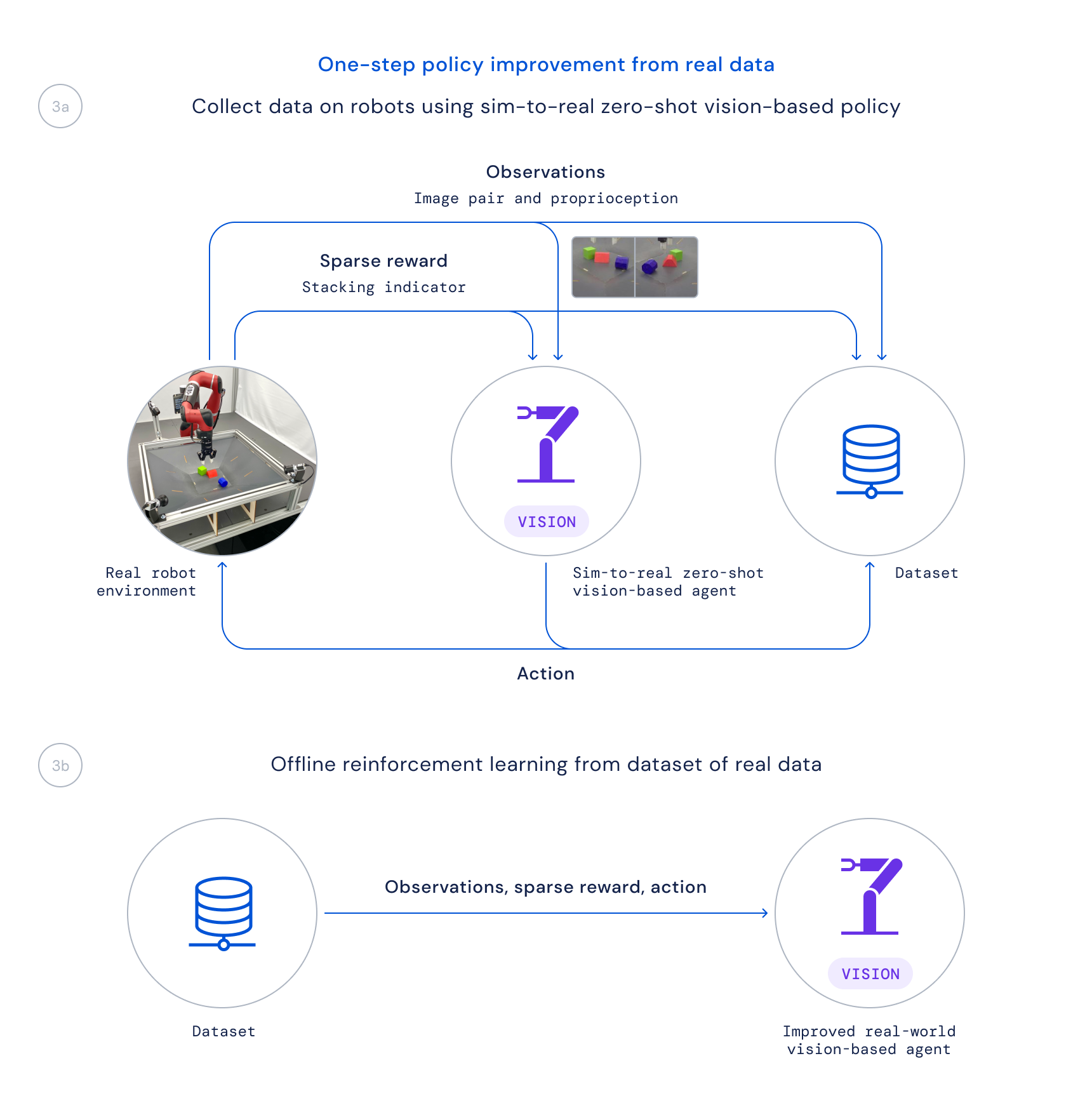
- Наконец, мы собираем данные, используя эту политику для реальных роботов, и обучаем улучшенную политику на основе этих данных в автономном режиме, взвешивая хорошие переходы на основе изученной функции Q, как это делается в Critic Regularized Regression (CRR). Это позволяет нам использовать данные, которые пассивно собираются во время проекта, вместо того, чтобы запускать трудоемкий онлайн-алгоритм обучения на реальных роботах.
Разделение нашего конвейера обучения таким образом оказывается крайне важным по двум основным причинам. Во-первых, это позволяет нам вообще решить проблему, так как это заняло бы слишком много времени, если бы мы начали с нуля непосредственно на роботах. Во-вторых, это увеличивает скорость наших исследований, поскольку разные люди в нашей команде могут работать над разными частями конвейера, прежде чем мы объединим эти изменения для общего улучшения.

В последние годы было проведено много работ по применению алгоритмов обучения для решения сложных задач манипулирования реальными роботами в масштабе, но основное внимание в этой работе уделялось таким задачам, как захват, толкание или другие формы манипулирования отдельными объектами. Подход к RGB-стекингу, который мы описываем в нашей статье, в сочетании с нашими ресурсами по робототехнике, теперь доступными на GitHub, приводит к удивительным стратегиям стекирования и мастерству стекирования подмножества этих объектов. Тем не менее, этот шаг лишь поверхностно касается того, что возможно, и проблема обобщения остается нерешенной. Поскольку исследователи продолжают работать над решением открытой задачи истинного обобщения в робототехнике, мы надеемся, что этот новый эталон, наряду с выпущенными нами средой, конструкциями и инструментами, внесет свой вклад в новые идеи и методы, которые могут сделать манипулирование еще проще, а роботов — более способными. .