
ТЛ;ДР: В RLHF существует противоречие между этапом обучения вознаграждению, который использует человеческие предпочтения в форме сравнений, и этапом точной настройки RL, который оптимизирует одно несравнимое вознаграждение. Что, если мы проведем RL сравнительным способом?
Рисунок 1:
Эта диаграмма иллюстрирует разницу между обучением с подкреплением абсолютный обратная связь и родственник обратная связь. Включив новый компонент — попарный градиент политики, мы можем объединить этап моделирования вознаграждения и этап RL, обеспечивая прямые обновления на основе парных ответов.
Модели больших языков (LLM) стали основой для все более эффективных виртуальных помощников, таких как GPT-4, Claude-2, Bard и Bing Chat. Эти системы могут отвечать на сложные запросы пользователей, писать код и даже создавать стихи. Технология, лежащая в основе этих удивительных виртуальных помощников, — это обучение с подкреплением и обратной связью с человеком (RLHF). RLHF стремится привести модель в соответствие с человеческими ценностями и устранить непреднамеренное поведение, которое часто может возникнуть из-за того, что модель подвергается воздействию большого количества данных низкого качества на этапе предварительного обучения.
Сообщается, что оптимизация проксимальной политики (PPO), доминирующий оптимизатор RL в этом процессе, демонстрирует нестабильность и сложности реализации. Что еще более важно, в процессе RLHF существует постоянное несоответствие: несмотря на то, что модель вознаграждения обучается с использованием сравнения различных ответов, этап тонкой настройки RL работает с отдельными ответами без каких-либо сравнений. Эта несогласованность может усугубить проблемы, особенно в сложной области создания языков.
На этом фоне возникает интригующий вопрос: возможно ли разработать алгоритм RL, который обучается сравнительным способом? Чтобы изучить это, мы представляем Pairwise Proximal Policy Optimization (P3O), метод, который гармонизирует процессы обучения как на этапе обучения с вознаграждением, так и на этапе тонкой настройки RL RLHF, обеспечивая удовлетворительное решение этой проблемы.
Фон
Фигура 2:
Описание трех этапов RLHF из сообщения в блоге OpenAI. Обратите внимание, что третий этап подпадает под обучение с подкреплением и абсолютной обратной связью, как показано в левой части рисунка 1.
В традиционных настройках RL награда указывается дизайнером вручную или предоставляется с помощью четко определенной функции вознаграждения, как в играх Atari. Однако направить модель на полезные и безобидные реакции, определить хорошее вознаграждение непросто. RLHF решает эту проблему, изучая функцию вознаграждения на основе отзывов людей, особенно в форме сравнений, а затем применяя RL для оптимизации изученной функции вознаграждения.
Конвейер RLHF разделен на несколько этапов, которые подробно описаны ниже:
Этап контролируемой тонкой настройки: Предварительно обученная модель подвергается максимальной потере правдоподобия в наборе данных высокого качества, где она учится реагировать на человеческие запросы посредством имитации.
Этап моделирования вознаграждения: Модель SFT выдает подсказки \(x\) для создания пар ответов \(y_1,y_2\sim \pi^{\text{SFT}}(y\vert x)\). Эти сгенерированные ответы образуют набор данных. Пары ответов предоставляются людям, размечающим ответы, которые выражают предпочтение одного ответа перед другим, что обозначается как \(y_w \succ y_l\). Сравнительные потери затем используются для обучения модели вознаграждения \(r_\phi\):
\[\mathcal{L}_R = \mathbb{E}_{(x,y_l,y_w)\sim\mathcal{D}}\log \sigma\left(r_\phi(y_w|x)-r_\phi(y_l|x)\right)\]
Этап тонкой настройки RL: Модель SFT служит инициализацией этого этапа, а алгоритм RL оптимизирует политику в направлении максимизации вознаграждения, одновременно ограничивая отклонение от начальной политики. Формально это осуществляется посредством:
\[\max_{\pi_\theta}\mathbb{E}_{x\sim \mathcal{D}, y\sim \pi_\theta(\cdot\vert x)}\left[r_\phi(y\vert x)-\beta D_{\text{KL}}(\pi_\theta(\cdot\vert x)\Vert \pi^{\text{SFT}}(\cdot\vert x))\right]\]
Неотъемлемой проблемой этого подхода является неуникальность вознаграждения. Например, при наличии функции вознаграждения \(r(y\vert x)\) простой сдвиг вознаграждения за подсказку на \(r(y\vert x)+\delta(x)\) создает другое допустимое вознаграждение. функция. Эти две функции вознаграждения приводят к одинаковым потерям для любых пар ответов, но они значительно различаются при оптимизации с помощью RL. В крайнем случае, если добавленный шум приведет к тому, что функция вознаграждения будет иметь большой диапазон, алгоритм RL может быть введен в заблуждение, чтобы увеличить вероятность ответов с более высокими вознаграждениями, даже если эти вознаграждения могут не иметь смысла. Другими словами, политика может быть нарушена информацией о шкале вознаграждений в подсказке \(x\), но она не сможет изучить полезную часть — относительное предпочтение, представленное разницей вознаграждений. Чтобы решить эту проблему, наша цель — разработать алгоритм RL, который инвариант вознаграждения за перевод.
Вывод P3O
Наша идея основана на ванильном политическом градиенте (VPG). VPG — широко распространенный оптимизатор RL первого порядка, популярный благодаря своей простоте и легкости реализации. В контексте контекстуального бандита (CB) VPG формулируется как:
\[\nabla \mathcal{L}^{\text{VPG}} = \mathbb{E}_{y\sim\pi_{\theta}} r(y|x)\nabla\log\pi_{\theta}(y|x)\]
С помощью некоторых алгебраических манипуляций мы можем переписать политический градиент в сравнительной форме, которая включает два ответа на одну и ту же подсказку. Мы называем это Парный градиент политики:
\[\mathbb{E}_{y_1,y_2\sim\pi_{\theta}}\left(r(y_1\vert x)-r(y_2\vert x)\right)\nabla\left(\log\frac{\pi_\theta(y_1\vert x)}{\pi_\theta(y_2\vert x)}\right)/2\]
В отличие от VPG, который напрямую зависит от абсолютной величины вознаграждения, PPG использует разницу вознаграждения. Это позволяет нам обойти вышеупомянутую проблему перевода вознаграждения. Для дальнейшего повышения производительности мы включаем буфер воспроизведения, используя Выборка по важности и избегайте больших обновлений градиента через Обрезка.
Выборка по важности: мы выбираем пакет ответов из буфера воспроизведения, который состоит из ответов, сгенерированных из \(\pi_{\text{old}}\), а затем вычисляем коэффициент выборки по важности для каждой пары ответов. Градиент представляет собой взвешенную сумму градиентов, вычисленных по каждой паре ответов.
Отсечение: мы отсекаем коэффициент выборки важности, а также обновление градиента, чтобы наказывать чрезмерно большие обновления. Этот метод позволяет алгоритму более эффективно компенсировать расхождение KL и вознаграждение.
Существует два разных способа реализации техники обрезки, отличающиеся раздельной или совместной обрезкой. Полученный алгоритм называется парной оптимизацией проксимальной политики (P3O), причем варианты имеют значения V1 или V2 соответственно. Более подробную информацию вы можете найти в нашей оригинальной статье.
Оценка
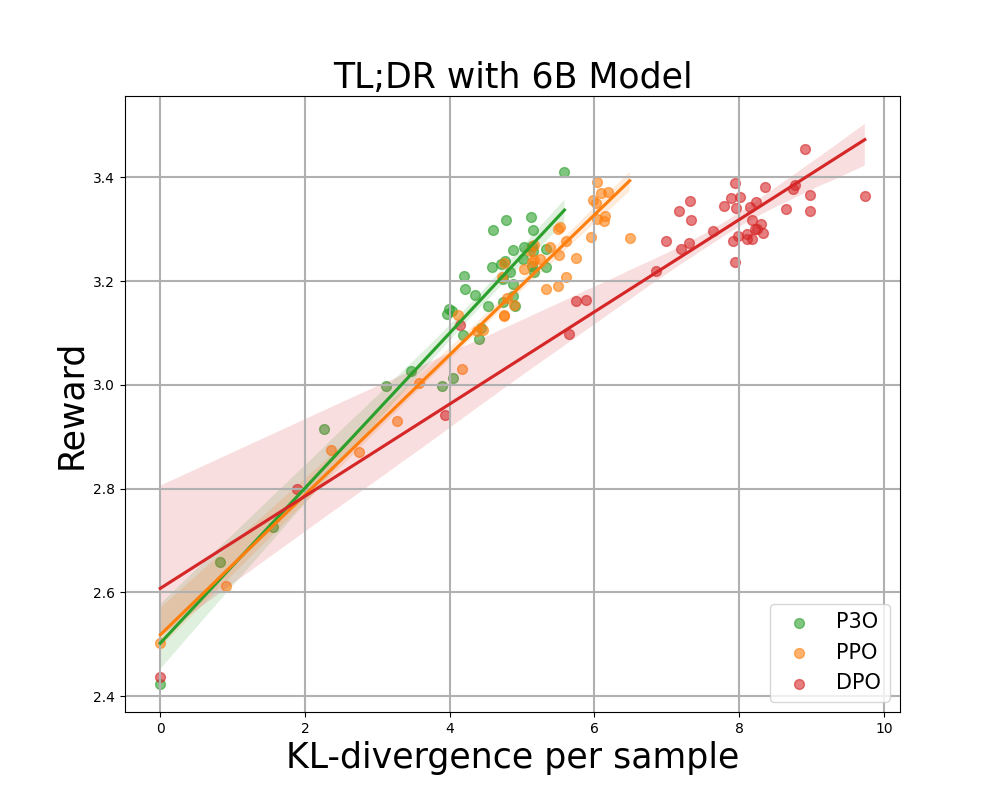
Рисунок 3:
Граница KL-Reward для TL;DR: KL и вознаграждение по последовательности усредняются по 200 тестовым запросам и вычисляются каждые 500 шагов градиента. Мы обнаружили, что простая линейная функция хорошо описывает кривую. P3O имеет лучшее соотношение KL-Reward среди трех.
Мы исследуем две разные задачи генерации открытого текста: обобщение и вопрос-ответ. Для обобщения мы используем набор данных TL;DR, где подсказка \(x\) — это сообщение на форуме Reddit, а \(y\) — соответствующее резюме. Для ответов на вопросы мы используем «Антропный полезный и безвредный» (HH), подсказка \(x\) — это человеческий запрос по различным темам, и политика должна научиться давать интересный и полезный ответ \(y\).
Сравниваем наш алгоритм P3O с несколькими эффективными и репрезентативными подходами к согласованию LLM. Мы начинаем с СФТ политика, обученная на основе максимального правдоподобия. Для алгоритмов RL мы рассматриваем доминирующий подход ППО и недавно предложенный ДПО. DPO напрямую оптимизирует политику в направлении решения в закрытой форме проблемы RL с ограничениями KL. Хотя он предлагается как метод выравнивания в автономном режиме, мы делаем его онлайн с помощью функции вознаграждения прокси.
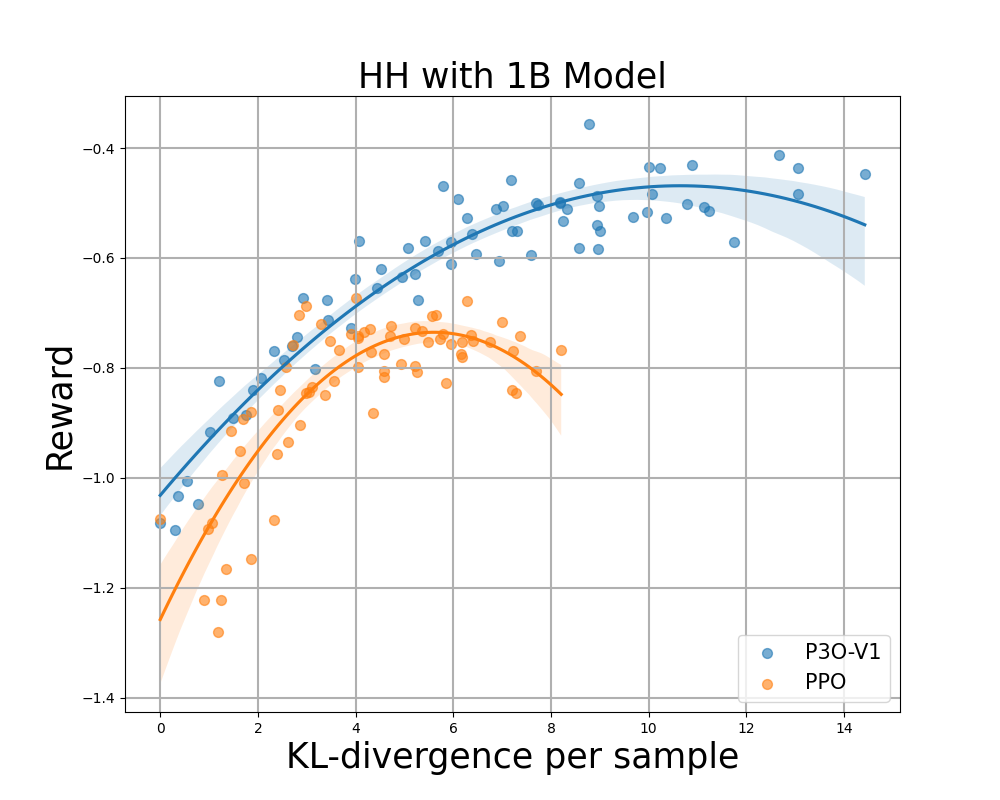
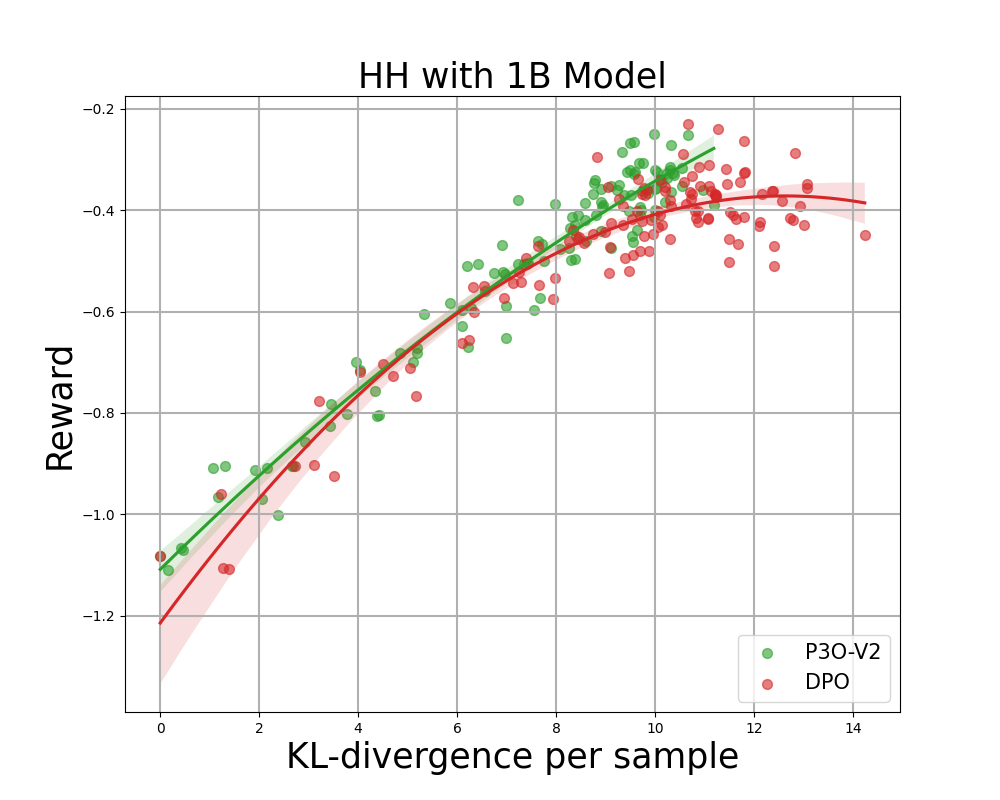
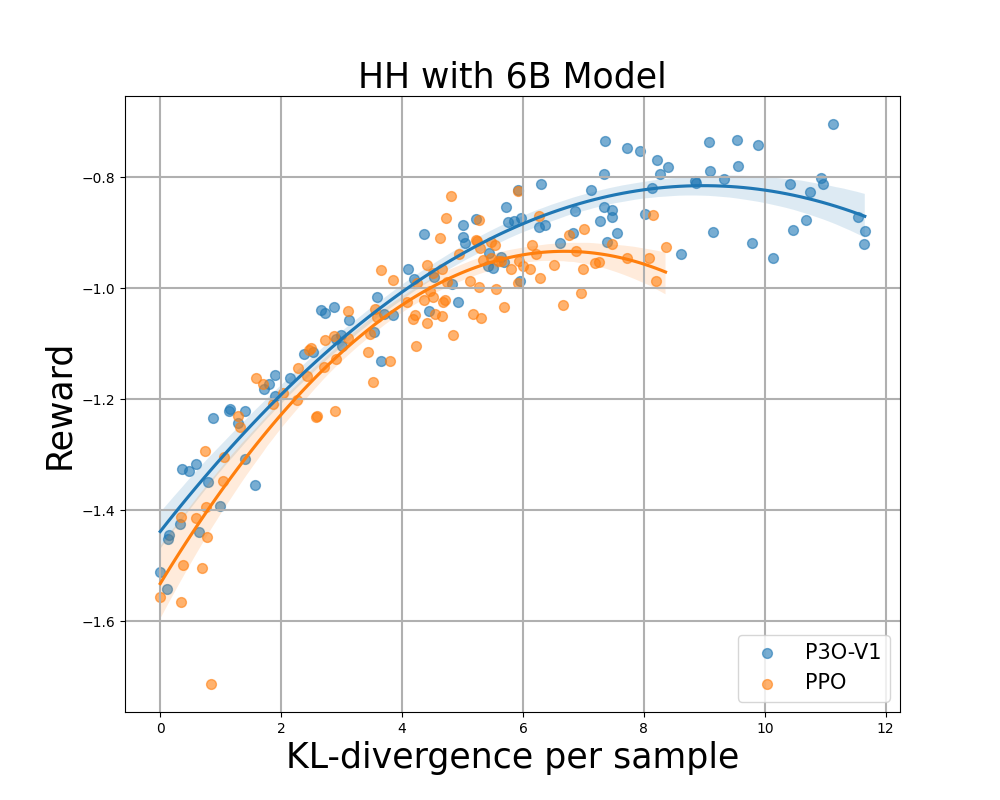
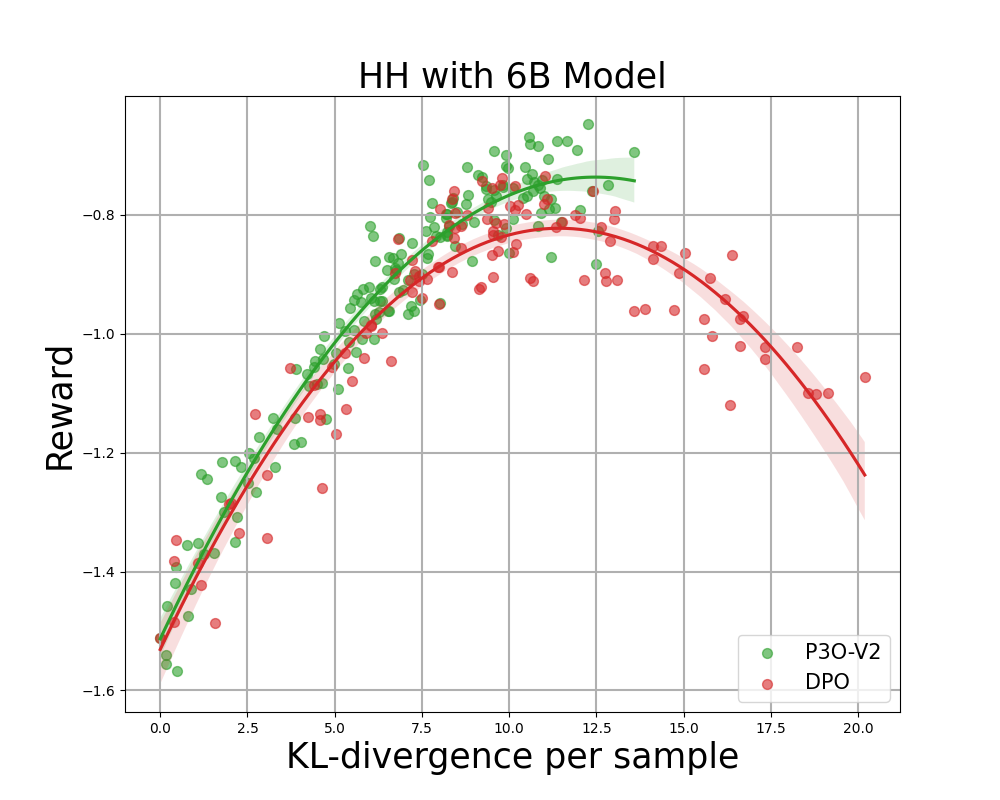
Рисунок 4:
Граница KL-Reward для HH: каждая точка представляет собой среднее значение результатов по 280 тестовым запросам и рассчитывается каждые 500 обновлений градиента. На двух рисунках слева сравниваются P3O-V1 и PPO с различными размерами базовой модели; Два рисунка справа сравнивают P3O-V2 и DPO. Результаты показывают, что P3O может не только добиться более высокого вознаграждения, но и улучшить контроль KL.
Слишком большое отклонение от эталонной политики приведет к тому, что онлайн-политика срежет углы модели вознаграждения и приведет к бессвязным продолжениям, как указывалось в предыдущих работах. Нас интересует не только устоявшаяся в литературе RL метрика — вознаграждение, но и то, насколько изученная политика отклоняется от первоначальной политики, измеряемой КЛ-дивергенцией. Поэтому мы исследуем эффективность каждого алгоритма по его границе достигнутого вознаграждения и KL-отклонению от эталонной политики (KL-Награда за границу). На рисунках 4 и 5 мы обнаруживаем, что P3O имеет строго доминирующие границы, чем PPO и DPO, в моделях разных размеров.
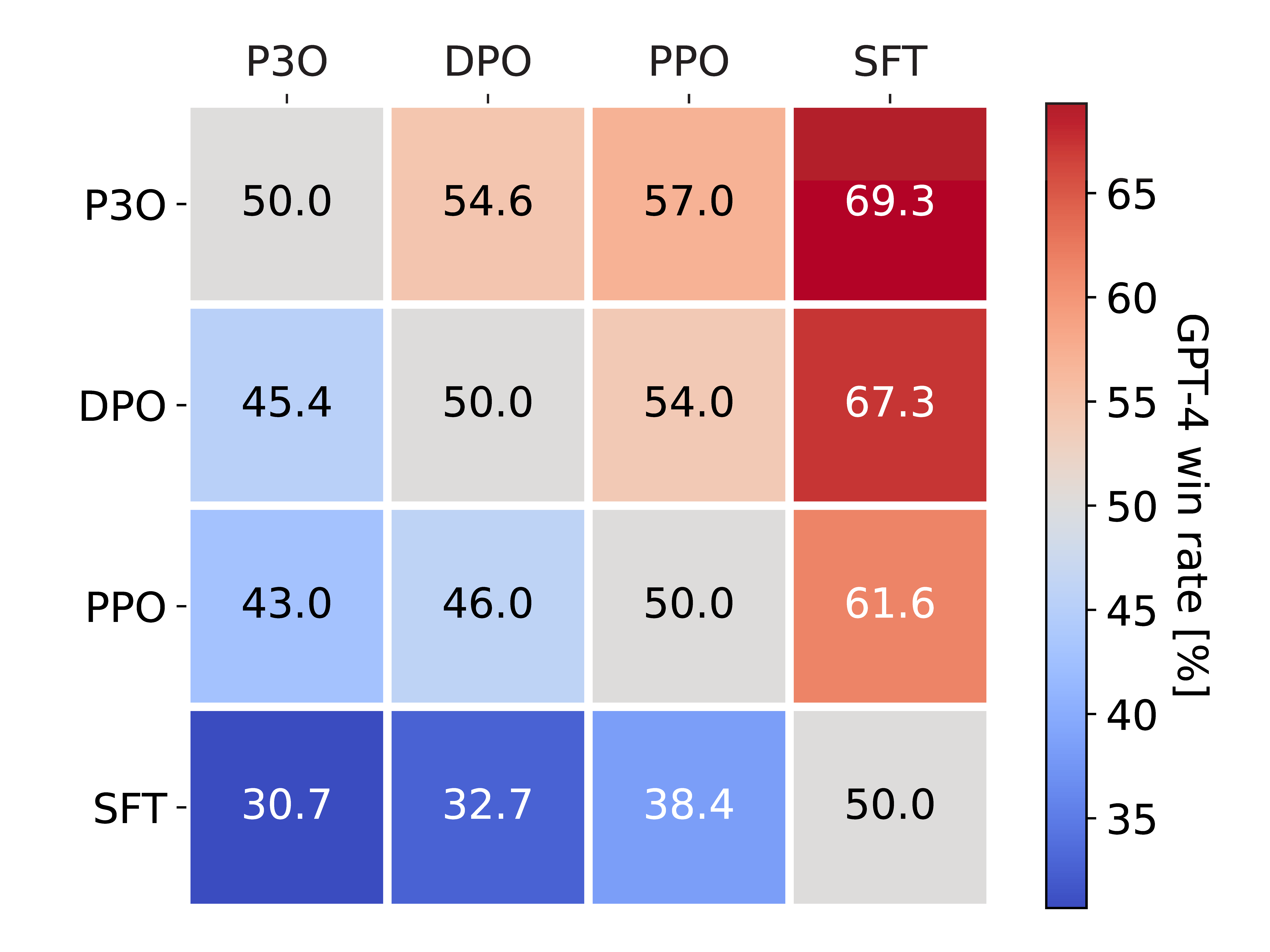
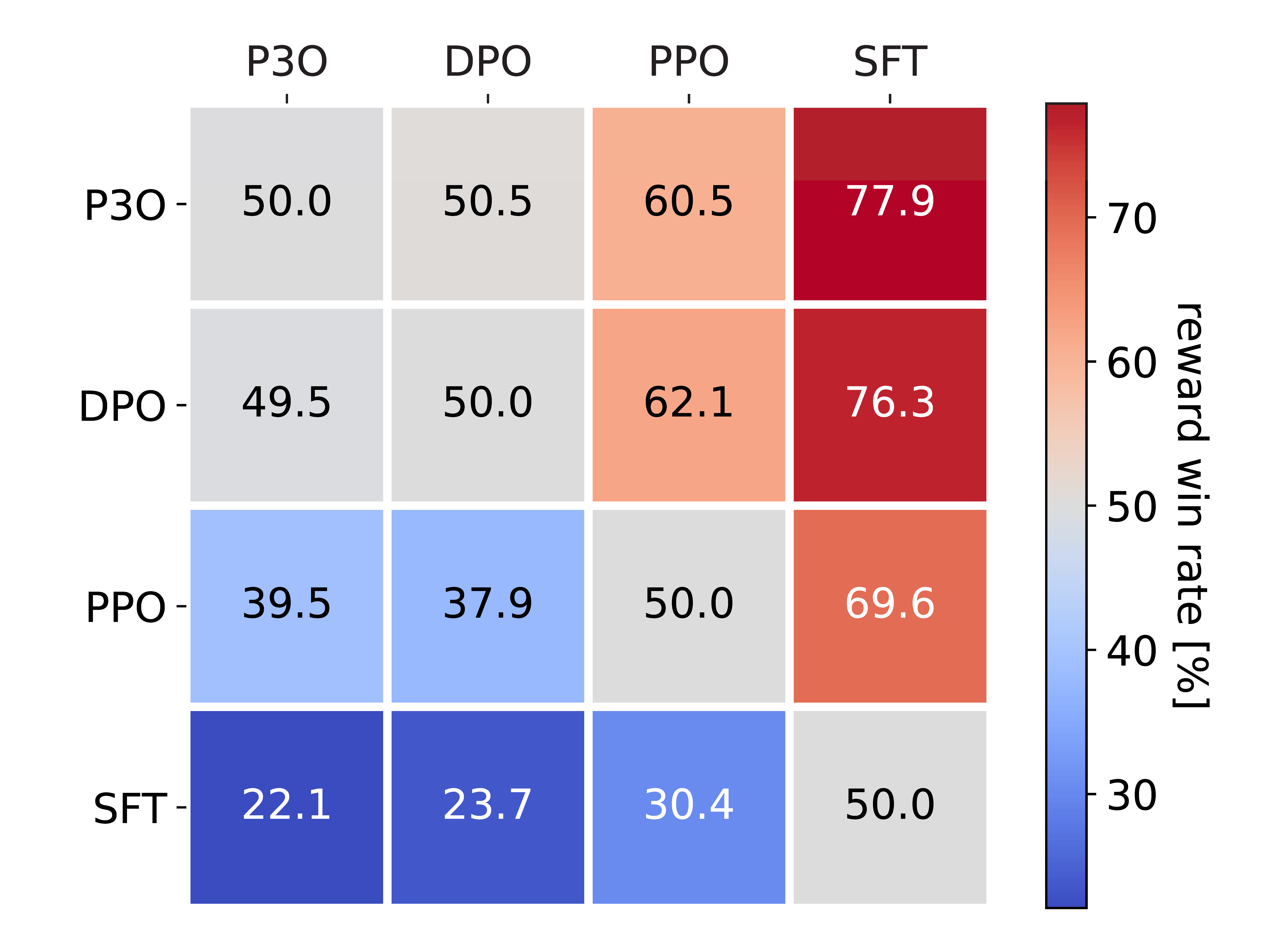
Рисунок 5:
На левом рисунке показан процент побед, оцененный GPT-4. На рисунке справа представлен процент выигрышей, основанный на прямом сравнении вознаграждения прокси. Несмотря на высокую корреляцию между двумя цифрами, мы обнаружили, что процент выигрышей в вознаграждениях необходимо корректировать в соответствии с KL, чтобы он соответствовал проценту выигрышей GPT-4.
Для непосредственной оценки качества генерируемых ответов мы также проводим Прямые сравнения между каждой парой алгоритмов в наборе данных HH. Для оценки мы используем две метрики: (1) Наградаоптимизированная цель во время онлайн-RL, (2) ГПТ-4, как верный показатель человеческой оценки полезности ответа. Что касается последнего показателя, мы отмечаем, что предыдущие исследования показывают, что суждения GPT-4 сильно коррелируют с людьми, при этом согласие человека с GPT-4 обычно аналогично или выше, чем согласие аннотаторов между людьми.
На рисунке 5 представлены полные результаты попарного сравнения. Средний рейтинг KL-дивергенции и вознаграждения для этих моделей составляет DPO > P3O > PPO > SFT. Хотя DPO незначительно превосходит P3O по вознаграждению, он имеет значительно более высокую KL-дивергенцию, что может отрицательно сказаться на качестве генерации. В результате DPO имеет коэффициент выигрыша вознаграждений 49,5% по сравнению с P3O, но только 45,4% по оценке GPT-4. По сравнению с другими методами P3O демонстрирует процент побед GPT-4 57,0% против PPO и 69,3% против SFT. Этот результат согласуется с нашими выводами по граничному показателю KL-Reward, подтверждающим, что P3O может лучше соответствовать человеческим предпочтениям, чем предыдущие базовые показатели.
Заключение
В этом сообщении блога мы представляем новые идеи по согласованию больших языковых моделей с человеческими предпочтениями с помощью обучения с подкреплением. Мы предложили структуру обучения с подкреплением с относительной обратной связью, как показано на рисунке 1. В рамках этой структуры мы разрабатываем новый алгоритм градиента политики – P3O. Этот подход объединяет фундаментальные принципы моделирования вознаграждения и тонкой настройки RL посредством сравнительного обучения. Наши результаты показывают, что P3O превосходит предыдущие методы с точки зрения границы KL-Reward, а также процента побед GPT-4.
БибТекс
Этот блог основан на нашей недавней статье и блоге. Если этот блог вдохновляет вас на работу, пожалуйста, процитируйте его:
@article{wu2023pairwise,
title={Pairwise Proximal Policy Optimization: Harnessing Relative Feedback for LLM Alignment},
author={Wu, Tianhao and Zhu, Banghua and Zhang, Ruoyu and Wen, Zhaojin and Ramchandran, Kannan and Jiao, Jiantao},
journal={arXiv preprint arXiv:2310.00212},
year={2023}
}