
{kind=link}
Как исследователи компьютерного зрения, мы считаем, что каждый пиксель может рассказать историю. Тем не менее, когда дело доходит до работы с большими изображениями, у писателя, похоже, возникает затруднение в работе с этой областью. Большие изображения больше не являются редкостью: камеры, которые мы носим в своих карманах, и те, что вращаются вокруг нашей планеты, делают снимки настолько большими и подробными, что при работе с ними наши лучшие на данный момент модели и оборудование растягиваются до предела. Как правило, мы сталкиваемся с квадратичным увеличением использования памяти в зависимости от размера изображения.
Сегодня при работе с большими изображениями мы делаем один из двух неоптимальных вариантов: понижение разрешения или обрезка. Эти два метода несут значительные потери в объеме информации и контекста изображения. Мы еще раз взглянем на эти подходы и представим $x$T, новую платформу для сквозного моделирования больших изображений на современных графических процессорах, эффективно объединяя глобальный контекст с локальными деталями.

Архитектура для платформы $x$T.
Зачем вообще беспокоиться о больших изображениях?
Зачем вообще обрабатывать большие изображения? Представьте себя перед телевизором и смотрите любимую футбольную команду. Поле усеяно игроками, и действия происходят только на небольшой части экрана одновременно. Однако были бы вы удовлетворены, если бы могли видеть только небольшую область вокруг того места, где в данный момент находился мяч? Альтернативно, было бы вам приятно смотреть игру в низком разрешении? Каждый пиксель рассказывает историю, независимо от того, насколько далеко они находятся друг от друга. Это верно во всех областях: от экрана телевизора до патологоанатома, просматривающего гигапиксельный слайд для диагностики крошечных участков рака. Эти изображения — кладезь информации. Если мы не можем полностью изучить это богатство, потому что наши инструменты не справляются с картой, какой в этом смысл?

Спорт – это весело, когда ты знаешь, что происходит.
Именно в этом и заключается сегодняшнее разочарование. Чем больше изображение, тем больше нам нужно одновременно уменьшать масштаб, чтобы увидеть всю картину, и увеличивать его, чтобы рассмотреть мельчайшие детали, что усложняет одновременное восприятие и леса, и деревьев. Большинство современных методов вынуждают выбирать между потерей леса из виду или отсутствием деревьев, и ни один из вариантов не является лучшим.
Как $x$T пытается это исправить
Представьте себе, что вы пытаетесь решить огромную головоломку. Вместо того, чтобы заниматься всем сразу, что было бы утомительно, вы начинаете с небольших разделов, внимательно рассматриваете каждый фрагмент, а затем выясняете, как они вписываются в общую картину. По сути, это то, что мы делаем с большими изображениями с помощью $x$T.
$x$T берет эти гигантские изображения и иерархически разбивает их на более мелкие, более удобоваримые части. Однако речь идет не только об уменьшении размеров. Речь идет о понимании каждой части по отдельности, а затем, используя некоторые умные методы, выяснении того, как эти части связаны в более широком масштабе. Это похоже на разговор с каждой частью изображения, изучение ее истории, а затем обмен этими историями с другими частями, чтобы получить полное повествование.
Вложенная токенизация
В основе $x$T лежит концепция вложенной токенизации. Проще говоря, токенизация в сфере компьютерного зрения сродни разделению изображения на части (токены), которые модель может переварить и проанализировать. Однако $x$T идет еще дальше, вводя в процесс иерархию — следовательно, вложенный.
Представьте, что вам поручено проанализировать подробную карту города. Вместо того, чтобы попытаться охватить всю карту сразу, вы разбиваете ее на районы, затем на кварталы внутри этих районов и, наконец, на улицы внутри этих кварталов. Такая иерархическая разбивка упрощает управление и понимание деталей карты, одновременно отслеживая, где все вписывается в общую картину. В этом суть вложенной токенизации — мы разбиваем изображение на регионы, каждый из которых может быть разделен на дополнительные подрегионы в зависимости от размера входных данных, ожидаемого магистралью видения (то, что мы называем кодировщик региона), прежде чем быть исправленным для обработки этим кодировщиком региона. Этот вложенный подход позволяет нам извлекать объекты разных масштабов на локальном уровне.
Координация кодировщиков региона и контекста
После того как изображение аккуратно разделено на токены, $x$T использует два типа кодировщиков для понимания этих частей: кодировщик региона и кодировщик контекста. Каждый из них играет особую роль в составлении полной истории изображения.
Кодер региона — это автономный «локальный эксперт», который преобразует независимые регионы в подробные представления. Однако, поскольку каждая область обрабатывается изолированно, никакая информация не передается по всему изображению. Кодер региона может быть любой современной магистральной системой машинного зрения. В наших экспериментах мы использовали иерархические преобразователи зрения, такие как Swin и Hiera, а также CNN, такие как ConvNeXt!
Введите кодировщик контекста, гуру общей картины. Его задача — взять подробные представления от кодировщиков регионов и объединить их вместе, гарантируя, что данные одного токена рассматриваются в контексте других. Кодер контекста обычно представляет собой модель длинной последовательности. Мы экспериментируем с Трансформером-XL (и нашим вариантом под названием Гипер) и Mamba, хотя вы можете использовать Longformer и другие новые достижения в этой области. Несмотря на то, что эти модели с длинными последовательностями обычно созданы для языка, мы показываем, что их можно эффективно использовать для задач зрения.
Магия $x$T заключается в том, как эти компоненты — вложенная токенизация, кодировщики регионов и кодировщики контекста — объединяются. Сначала разбивая изображение на управляемые части, а затем систематически анализируя эти части как по отдельности, так и вместе, $x$T удается сохранить точность деталей исходного изображения, а также интегрировать удаленный контекст в общий контекст. при комплексной установке огромных изображений на современные графические процессоры.
Полученные результаты
Мы оцениваем $x$T на сложных эталонных задачах, которые охватывают как хорошо зарекомендовавшие себя базовые показатели компьютерного зрения, так и строгие задачи с большими изображениями. В частности, мы экспериментируем с iNaturalist 2018 для детальной классификации видов, xView3-SAR для контекстно-зависимой сегментации и MS-COCO для обнаружения.
Мощные модели видения, используемые с $x$T, открывают новые горизонты в решении последующих задач, таких как детальная классификация видов.
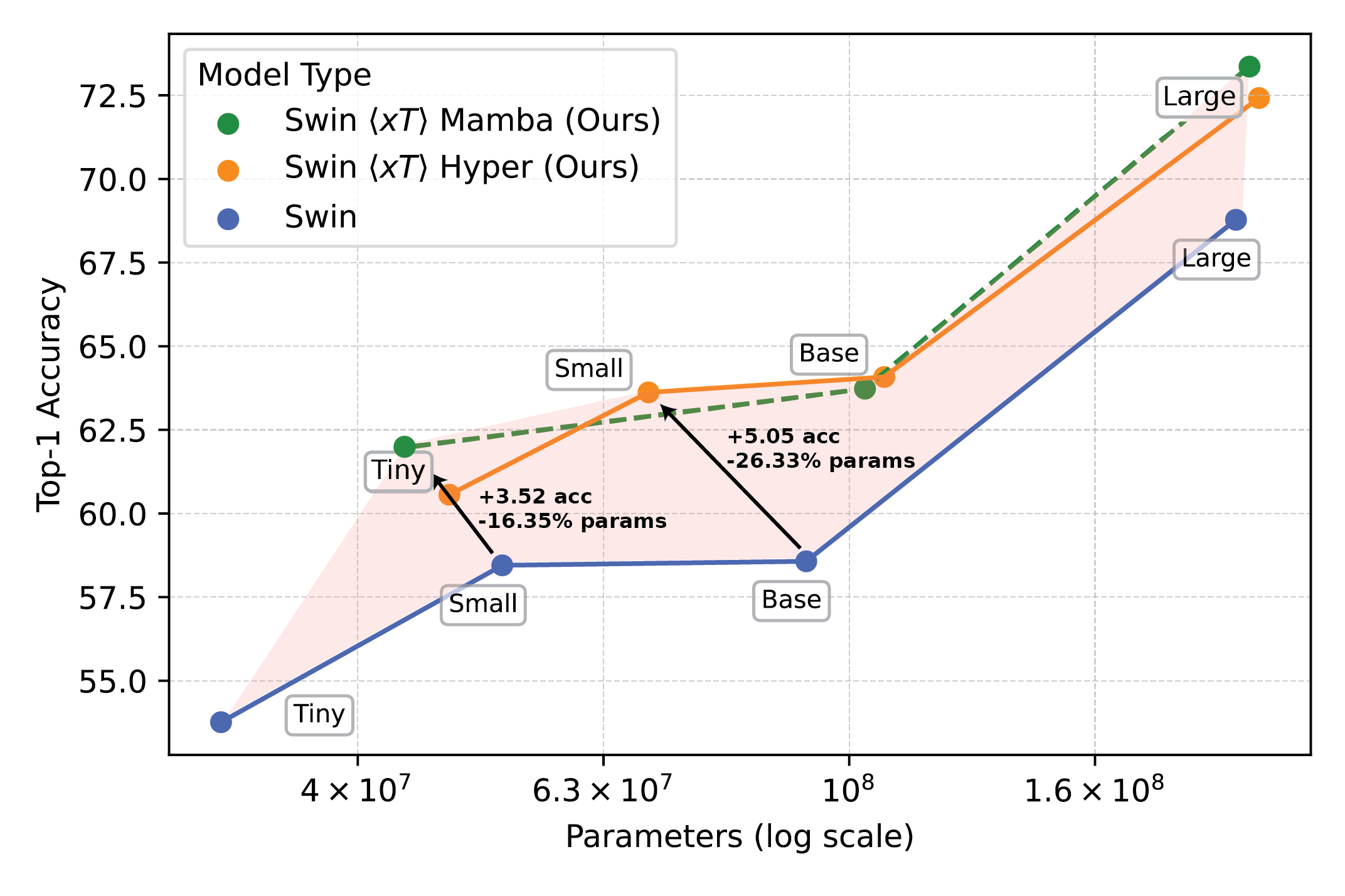
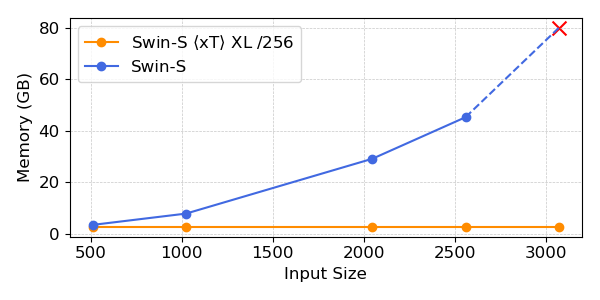
Наши эксперименты показывают, что $x$T может достичь более высокой точности во всех последующих задачах с меньшим количеством параметров, используя при этом гораздо меньше памяти на регион, чем современные базовые показатели.*. Мы можем моделировать изображения размером до 29 000 x 25 000 пикселей на устройствах A100 емкостью 40 ГБ, в то время как сопоставимые базовые изображения исчерпывают память при размере всего 2800 x 2800 пикселей.
Мощные модели видения, используемые с $x$T, открывают новые горизонты в решении последующих задач, таких как детальная классификация видов.
*В зависимости от вашего выбора контекстной модели, например Transformer-XL..
Почему это важнее, чем вы думаете
Этот подход не просто крут; необходимо. Для ученых, отслеживающих изменение климата, или врачей, диагностирующих заболевания, это меняет правила игры. Это означает создание моделей, которые понимают всю историю, а не только ее фрагменты. Например, в мониторинге окружающей среды возможность увидеть как более широкие изменения на обширных ландшафтах, так и детали конкретных территорий может помочь понять более широкую картину воздействия на климат. В здравоохранении это может означать разницу между ранним выявлением заболевания или нет.
Мы не претендуем на то, что решили все мировые проблемы за один раз. Мы надеемся, что с $x$T мы открыли дверь к возможному. Мы вступаем в новую эру, когда нам не придется идти на компромисс в отношении ясности и широты нашего видения. $x$T — это наш большой шаг к моделям, которые могут без труда справляться с тонкостями крупномасштабных изображений.
Нам еще многое предстоит охватить. Исследования будут развиваться, и, будем надеяться, вместе с нами будет развиваться и наша способность обрабатывать еще большие и сложные изображения. Фактически, мы работаем над продолжением $x$T, которое еще больше расширит эти границы.
В заключение
Полное описание этой работы можно найти в статье на arXiv. Страница проекта содержит ссылку на наш выпущенный код и веса. Если вы считаете работу полезной, пожалуйста, дайте ссылку на нее, как показано ниже:
@article{xTLargeImageModeling,
title={xT: Nested Tokenization for Larger Context in Large Images},
author={Gupta, Ritwik and Li, Shufan and Zhu, Tyler and Malik, Jitendra and Darrell, Trevor and Mangalam, Karttikeya},
journal={arXiv preprint arXiv:2403.01915},
year={2024}
}