
{kind=link}
Активационная функция – это то, что формирует выход нейрона. Это то, что добавляет нелинейности вашему прогнозу и делает предиктор на основе нейронной сети намного лучше, чем линейные модели.
Обычно мы задаем себе вопрос: какую функцию активации следует использовать?
Ответ заключается в том, что на этот вопрос не существует универсального ответа. Это зависит.
Позвольте мне рассказать вам о наиболее часто используемых функциях активации, их плюсах и минусах, чтобы помочь вам принять правильное решение.
Мы можем определить наши собственные функции активации, которые наилучшим образом соответствуют нашим потребностям, наиболее часто используемые из них:
1. Активация сигмовидной кишки
2. Тан гиперболическая активация
3. ReLU (выпрямленная линейная единица)
4. Дырявый ReLU
Вот так выглядит каждый из них:
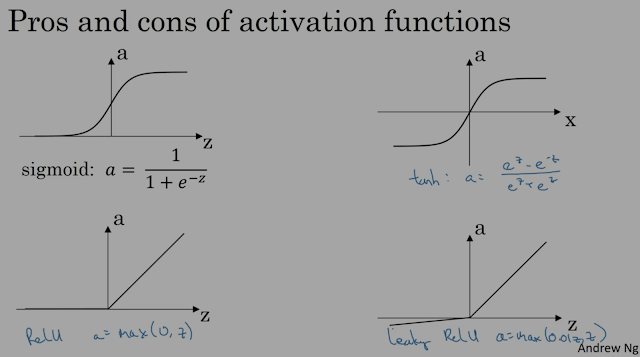
Источник фото: Специализация DeepLearning.ai
1. Активация сигмовидной кишки
Сигмовидная активация находится в диапазоне от 0 до 1. Это похоже на обычную «S-образную» кривую, которую мы наблюдаем в разных областях исследований.
Плюсы:
Просто – логика и арифметика
Предлагает хорошую нелинейность
Вывод естественной вероятности – от 0 до 1 для задач классификации.
Минусы:
Сеть перестает обучаться, когда вы приближаете значения к крайним точкам сигмоиды. Это называется проблемой исчезающих градиентов.
2. Загар гиперболический
Это в значительной степени сигмоид в расширенном диапазоне (от -1 до 1).
Плюсы:
Это увеличивает устойчивый нелинейный диапазон в середине сигмоиды до того, как наклон/градиент выровняется. Этот увеличенный диапазон помогает сети быстрее обучаться.
Минусы:
Эта активация ограничивает проблему исчезающих градиентов на концах сигмоиды до определенного уровня, но у нас есть лучшие варианты для более быстрого обучения.
3. РеЛУ
Исправлено – МАКС(0,значение)
Линейный – для z > 0 (положительные значения)
ReLU — это причудливое название для линейной функции только с положительными значениями. Для отрицательных прогнозов модуль имеет наклон 0. Однако для положительных активаций сеть, безусловно, может обучаться намного быстрее с линейным наклоном.
Плюсы:
Учится быстрее.
Наклон равен 1, если z положительно.
Минусы:
Пока не нашел 🙂
4. Дырявый ReLU
Это обеспечивает небольшой наклон для отрицательных значений предсказания нейрона. Это улучшение по сравнению с ReLU.
Эти нелинейные активации помогают улучшить и заложить основу для нейронных сетей.
До скорого!