
{kind=link}
В последние годы обучение с подкреплением (RL) добилось огромного прогресса в решении реальных проблем, а автономное RL сделало его еще более практичным. Вместо прямого взаимодействия с окружающей средой мы теперь можем обучать множество алгоритмов из одного предварительно записанного набора данных. Однако мы теряем практические преимущества автономного RL в эффективности данных, когда оцениваем имеющиеся политики.
Например, при обучении роботов-манипуляторов ресурсы роботов обычно ограничены, и обучение многих политик с помощью автономного RL на одном наборе данных дает нам большое преимущество в эффективности данных по сравнению с онлайн RL. Оценка каждой политики — дорогостоящий процесс, который требует тысяч взаимодействий с роботом. Когда мы выбираем лучший алгоритм, гиперпараметры и количество шагов обучения, проблема быстро становится неразрешимой.
Чтобы сделать RL более применимым к реальным приложениям, таким как робототехника, мы предлагаем использовать интеллектуальную процедуру оценки для выбора политики для развертывания, называемую активным выбором политики в автономном режиме (A-OPS). В A-OPS мы используем предварительно записанный набор данных и допускаем ограниченное взаимодействие с реальной средой для повышения качества выбора.
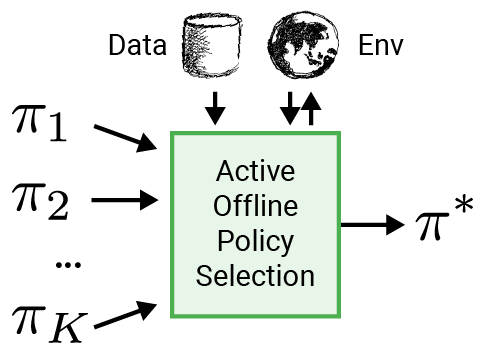
Чтобы свести к минимуму взаимодействие с реальной средой, мы реализуем три ключевые функции:
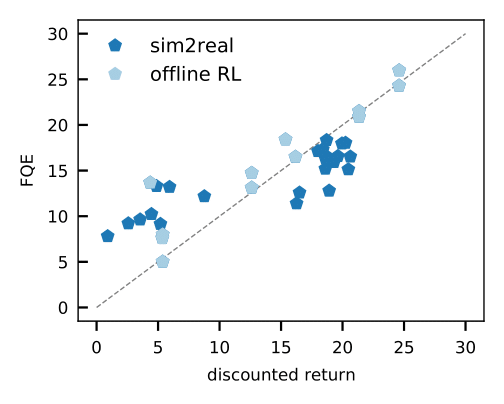
- Оценка политики вне политики, такая как подогнанная Q-оценка (FQE), позволяет нам сделать начальное предположение о производительности каждой политики на основе автономного набора данных. Он хорошо коррелирует с реальными характеристиками во многих средах, включая реальную робототехнику, где он применяется впервые.
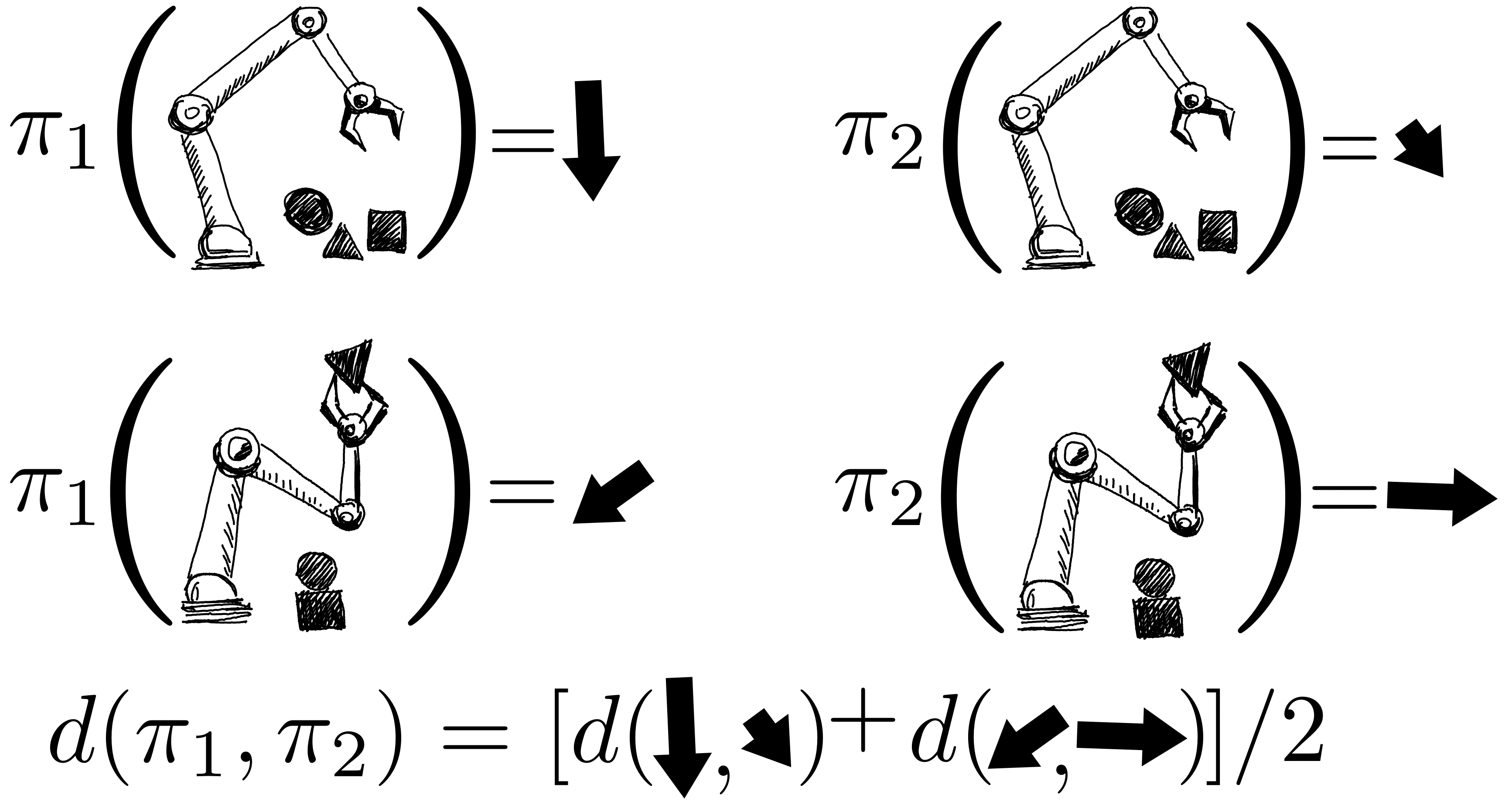
Возвраты политик моделируются совместно с использованием гауссовского процесса, где наблюдения включают оценки FQE и небольшое количество вновь собранных эпизодических возвратов от робота. Оценив одну политику, мы получаем информацию обо всех политиках, поскольку их распределения коррелируются через ядро между парами политик. Ядро предполагает, что если политики предпринимают аналогичные действия — например, перемещают роботизированный захват в одинаковом направлении — они, как правило, имеют схожие результаты.
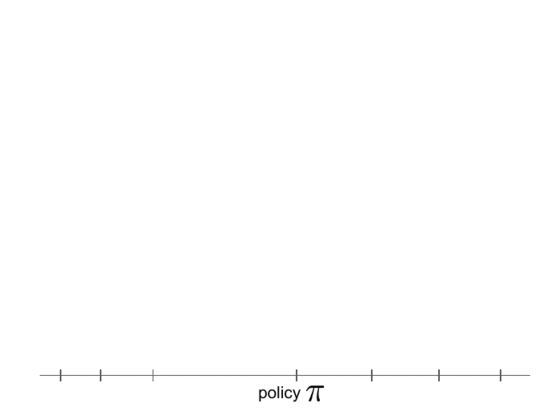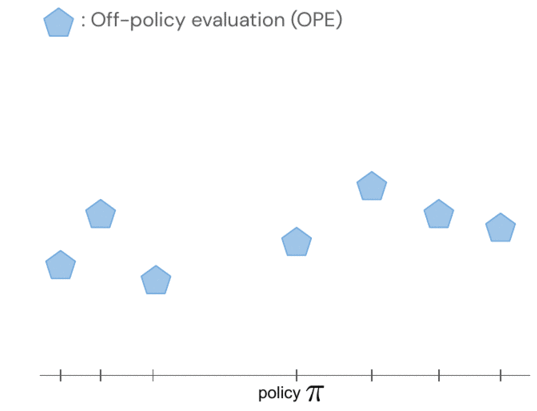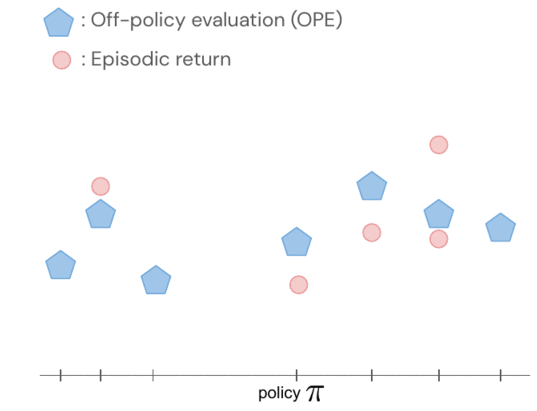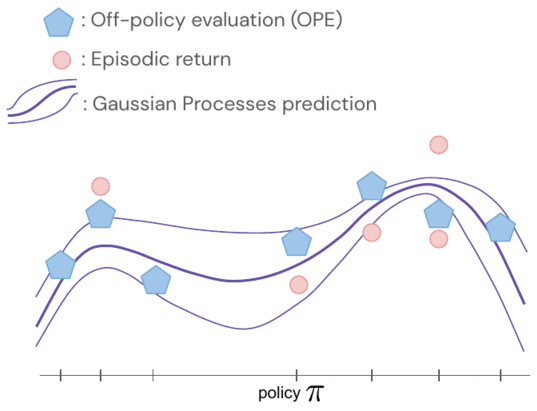
- Чтобы быть более эффективными с данными, мы применяем байесовскую оптимизацию и отдаем приоритет более перспективным политикам, которые будут оцениваться следующими, а именно тем, которые имеют высокую прогнозируемую производительность и большую дисперсию.
Мы продемонстрировали эту процедуру в ряде сред в нескольких областях: dm-control, Atari, смоделированная и реальная робототехника. Использование A-OPS быстро уменьшает сожаление, и с помощью небольшого количества оценок политики мы определяем лучшую политику.
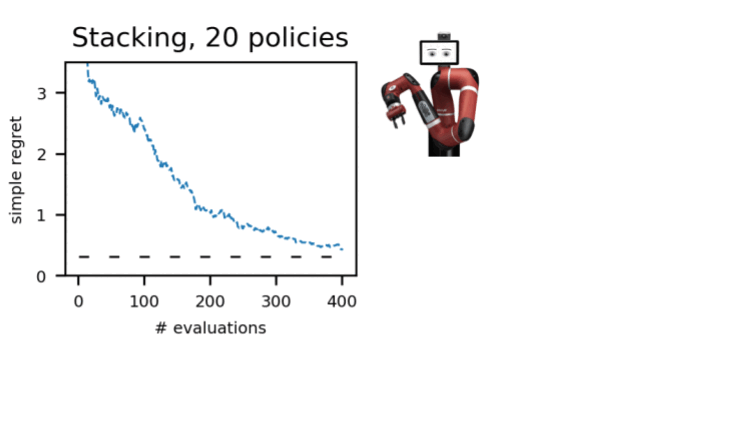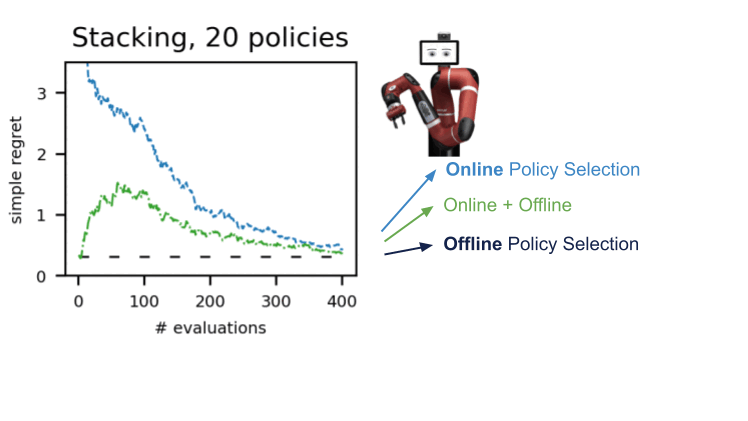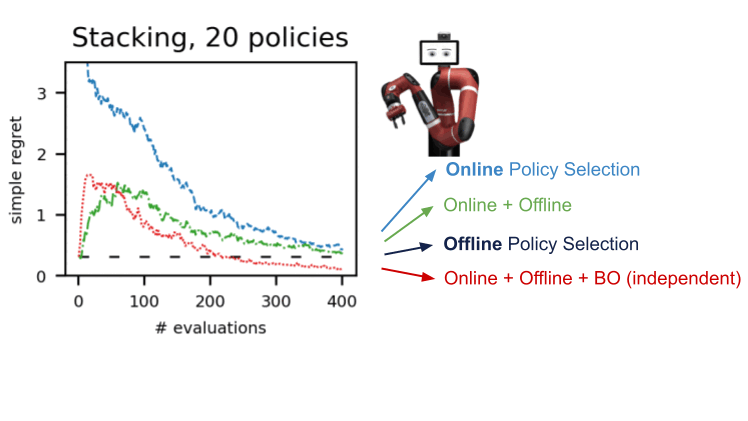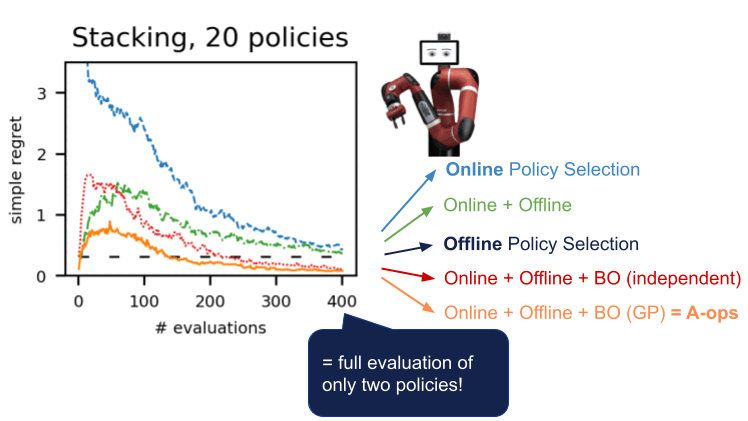
Наши результаты показывают, что можно сделать эффективный выбор политики в автономном режиме с небольшим количеством взаимодействий со средой, используя автономные данные, специальное ядро и байесовскую оптимизацию. Код для A-OPS имеет открытый исходный код и доступен на GitHub с примерным набором данных, который можно попробовать.