
Использование движений человека и животных для обучения роботов ведению мяча и имитация гуманоидных персонажей для переноски коробок и игры в футбол.

Пять лет назад мы взяли на себя задачу научить полностью подвижного гуманоидного персонажа преодолевать полосы препятствий. Это продемонстрировало, чего можно достичь с помощью обучения с подкреплением (RL) путем проб и ошибок, но также выявило две проблемы в решении воплощенный интеллект:
- Повторное использование ранее изученного поведения: Чтобы агент «оторвался от земли», требовался значительный объем данных. Без каких-либо начальных знаний о том, какую силу прикладывать к каждому из его суставов, агент начал с случайных подергиваний тела и быстрого падения на землю. Эту проблему можно решить, повторно используя ранее изученное поведение.
- Идиосинкразическое поведение: Когда агент, наконец, научился преодолевать полосу препятствий, он делал это с неестественными (хотя и забавными) моделями движения, которые были бы непрактичны для таких приложений, как робототехника.
Здесь мы описываем решение обеих проблем, называемых нейронно-вероятностными двигательными примитивами (NPMP), включающее управляемое обучение с моделями движений, полученными от людей и животных, и обсуждаем, как этот подход используется в нашей статье Humanoid Football, опубликованной сегодня в Science Robotics.
Мы также обсудим, как этот же подход позволяет манипулировать всем телом гуманоида с помощью зрения, например, гуманоид, несущий объект, и управлять роботом в реальном мире, например, роботом, ведущим мяч.
Преобразование данных в управляемые примитивы двигателя с использованием NPMP
NPMP — это модуль управления двигателем общего назначения, который переводит моторные намерения короткого горизонта в управляющие сигналы низкого уровня, и он обучается в автономном режиме или через RL путем имитации данных захвата движения (MoCap), записанных с помощью трекеров на людях или животных, выполняющих движения. интерес.

Модель состоит из двух частей:
- Кодер, который берет будущую траекторию и сжимает ее в моторное намерение.
- Низкоуровневый контроллер, производящий следующее действие с учетом текущего состояния агента и этого двигательного намерения.
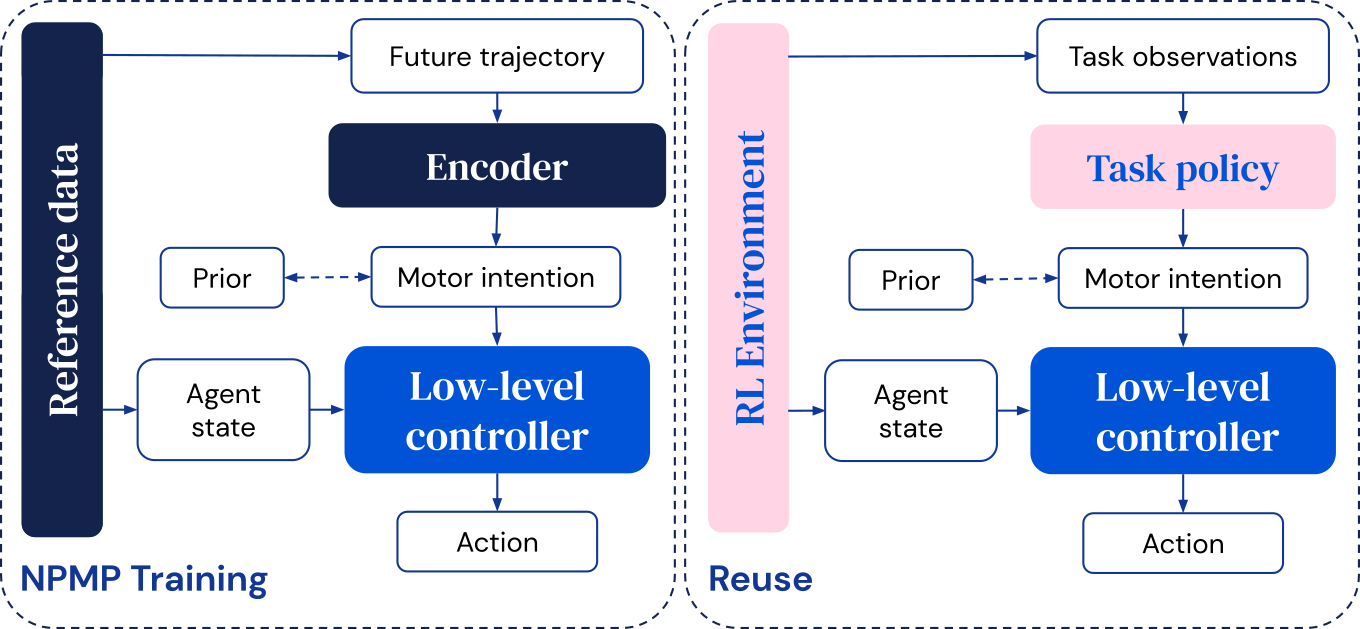
После обучения низкоуровневый контроллер можно повторно использовать для изучения новых задач, где высокоуровневый контроллер оптимизирован для непосредственного вывода двигательных намерений. Это обеспечивает эффективное исследование — поскольку последовательное поведение создается даже при случайно выбранных двигательных намерениях — и ограничивает окончательное решение.
Срочная командная координация в гуманоидном футболе
Футбол был давней проблемой для исследования воплощенного интеллекта, требуя индивидуальных навыков и скоординированной командной игры. В нашей последней работе мы использовали NPMP в качестве руководства для изучения двигательных навыков.
Результатом стала команда игроков, которые прошли путь от обучения навыкам преследования мяча до обучения координации. Ранее, в исследовании с простыми вариантами, мы показали, что скоординированное поведение может возникнуть в командах, конкурирующих друг с другом. NPMP позволил нам наблюдать аналогичный эффект, но в сценарии, который требовал значительно более продвинутого управления двигателем.


Наши агенты приобрели навыки, включая быстрое передвижение, передачу и разделение труда, о чем свидетельствует ряд статистических данных, включая показатели, используемые в реальной спортивной аналитике. Игроки демонстрируют как подвижный высокочастотный двигательный контроль, так и долгосрочное принятие решений, предполагающее поведение товарищей по команде, что приводит к скоординированной командной игре.

Манипуляции со всем телом и когнитивные задачи с использованием зрения
Научиться взаимодействовать с объектами с помощью рук — еще одна сложная задача управления. NPMP также может включать этот тип манипуляций со всем телом. Имея небольшое количество данных MoCap о взаимодействии с коробками, мы можем обучить агента переносить коробку из одного места в другое, используя эгоцентрическое видение и лишь скудный сигнал вознаграждения:


Точно так же мы можем научить агента ловить и бросать мячи:
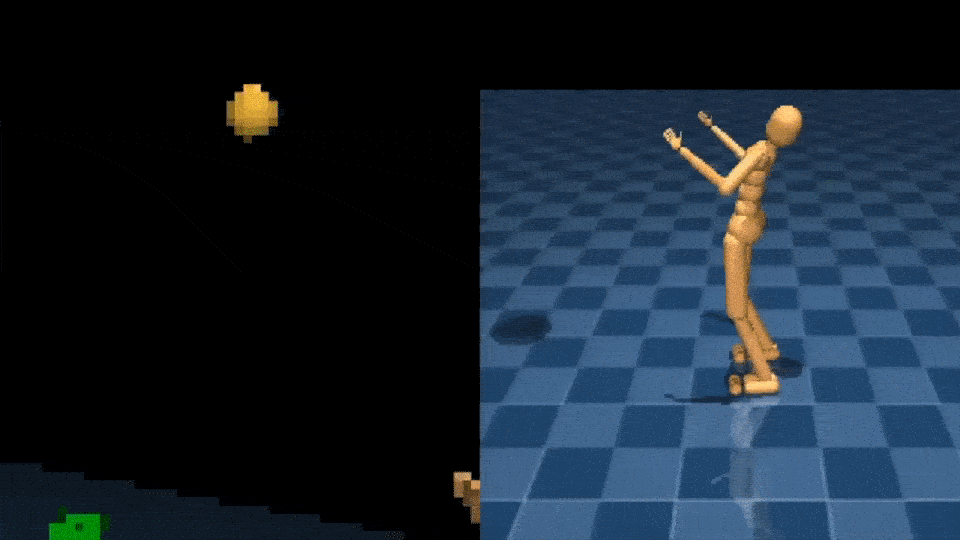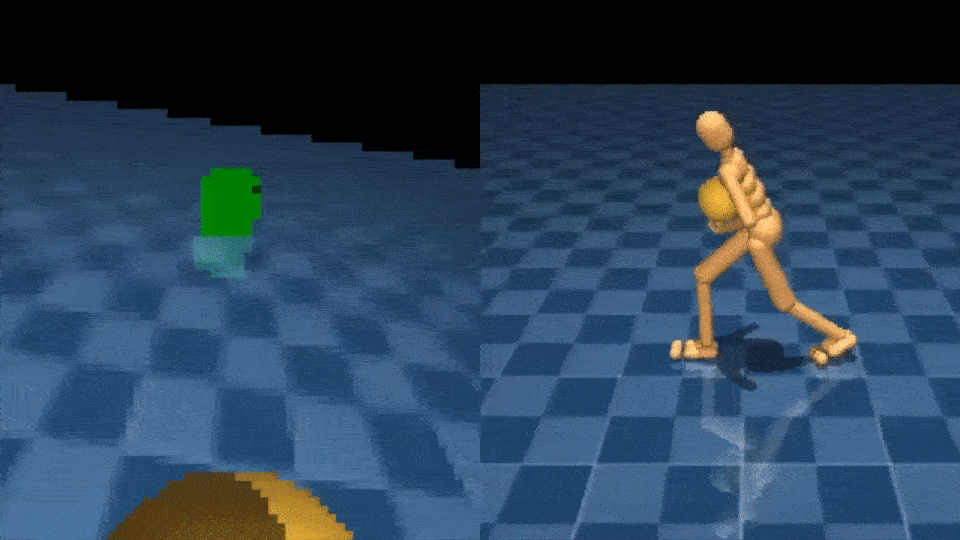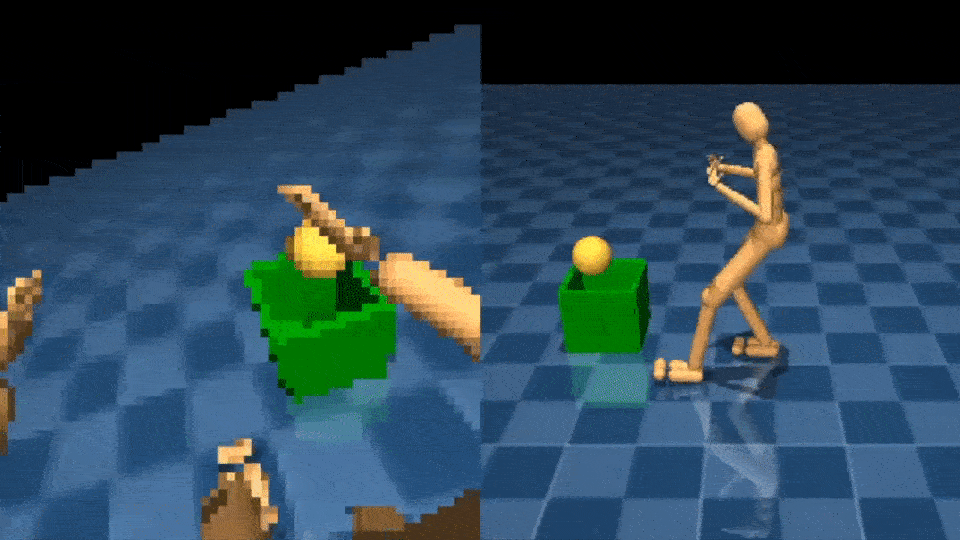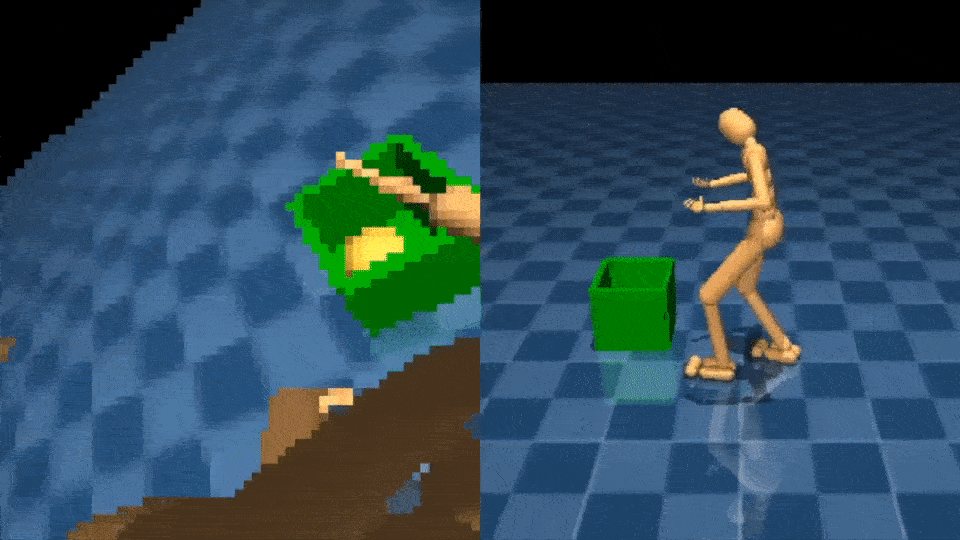
Используя NPMP, мы также можем решать задачи лабиринта, связанные с передвижением, восприятием и памятью:

Безопасное и эффективное управление реальными роботами
NPMP также может помочь управлять настоящими роботами. Наличие хорошо отрегулированного поведения имеет решающее значение для таких действий, как ходьба по пересеченной местности или обращение с хрупкими предметами. Нервные движения могут повредить самого робота или его окружение или, по крайней мере, разрядить его аккумулятор. Поэтому значительные усилия часто вкладываются в разработку целей обучения, которые заставляют робота делать то, что мы от него хотим, при этом ведя себя безопасным и эффективным образом.
В качестве альтернативы мы исследовали, может ли использование априорных данных, полученных из биологического движения, дать нам хорошо упорядоченные, естественные и повторно используемые навыки движения для роботов с ногами, такие как ходьба, бег и повороты, которые подходят для развертывания на реальных роботах. .
Начав с данных MoCap от людей и собак, мы адаптировали подход NPMP для обучения навыкам и контроллерам в моделировании, которое затем можно развернуть на реальных человекоподобных (OP3) и четвероногих (ANYmal B) роботах соответственно. Это позволяло пользователю управлять роботами с помощью джойстика или вести мяч в нужное место естественным и надежным способом.



Преимущества использования нейронных вероятностных двигательных примитивов
Таким образом, мы использовали модель навыков NPMP для изучения сложных задач с гуманоидными персонажами в симуляции и с реальными роботами. NPMP упаковывает низкоуровневые двигательные навыки многократно используемым образом, облегчая изучение полезного поведения, которое было бы трудно обнаружить методом неструктурированных проб и ошибок. Используя захват движения в качестве источника предварительной информации, он смещает изучение моторного контроля в сторону естественного движения.
NPMP позволяет встроенным агентам быстрее обучаться с помощью RL; научиться более натуралистическому поведению; научиться более безопасному, эффективному и стабильному поведению, подходящему для реальной робототехники; и сочетать двигательный контроль всего тела с более долгосрочными когнитивными навыками, такими как работа в команде и координация.
Узнайте больше о нашей работе: